
 Sophos Naked Security
Sophos Naked Security Securelist
Securelist cyber-secret futurist
cyber-secret futurist I'm, the bookworm
I'm, the bookworm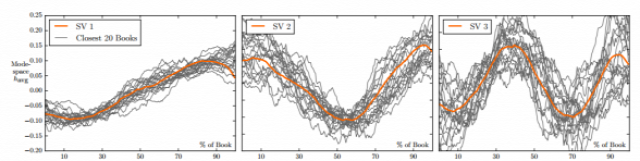
Egy nemrég megjelent publikáció szerint, amiben novellák, regények és más irodalmi művek ezreit elemezték főleg az ún. szentiment analízis módszerére támaszkodva megállapították, hogy a világirodalomban kortól és kultúrától függetlenül mi tett egy-egy irodalmi alkotást klasszikussá.
Maga Vonnegut már az 1990-es évek derekán feltételezte, hogy a legnagyobb műveknek lehetnek közös jellemzői, kérdéses volt, hogy ezt sikerül-e valaha kimutatni kvantitatív módszerekkel. A kutatók arra jutottak, hogy a világirodalom legnagyobb műveiben maga a sztori – ha jól értem – bizonyos emocionális íveket tesz meg, ennek megfelelő érzetek sorozatát kiváltva a befogadóban függetlenül attól, hogy azt olvassa vagy például filmen nézi. Összesen hat ilyen patternt sikerült azonosítani, a teljes cikk [The emotional arcs of stories are dominated by six basic shapes ] nem éppen könnyed olvasmány, barátságosabb változata a MIT Tech Reviewban jelent meg nemrég.
Személyes véleményem, hogy az adatelemzés módszerei már nem is olyan kevés ideje rendelkezésre álltak ugyan, valójában csak néhány évvel ezelőtt, a cloud computing általánossá váltásával vált elérhetővé olyan mértékű számítási kapacitás elérhető áron, ami elhozta azt, amit ma big data-érának nevezünk.
Ebbe a világba engedett egy mélyebb, messzemenően szakmai betekintést a közel két hónappal ezelőtt megtartott Nextent által támogatott Big Data Universe 2016 konferencia Budapesten, az előadások közül három, egymástól nagyban eltérő felhasználási területet emelek ki példaként.
Ma már gépi tanulást használó algoritmusok segítik az informatikai biztonsági incidensek kezelését, ami természetesen csak akkor lehet hatékony, ha az valós időben történik. A magatartás-elemzésen alapuló behatolásérzékelő Blindspotter ha átlagosan 7 percenként ad ki riasztást szokatlan felhasználói aktivitás miatt, nyilvánvaló, hogy lehetetlen kivizsgálni ezeket külön-külön annak megállapításához, hogy valódi támadásról van-e szó.
Egyre gyakrabban van szükség big datából átvett módszerek bevetésére a nyelvtechnológia területén is. Egyre gyakrabban felmerülő igény egy-egy óriáscég vagy például politikai párt számára, hogy képet kapjon azzal kapcsolatban, hogy hogyan is változott a tömeg velük kapcsolatos megítélése, aminek kézenfekvő adatforrása az interneten adott időintervallumban keletkezett, főként közösségi médiából származó szöveges felhasználói tartalmak elemzése. A pozitív és negatív jelzők megkülönböztetése már rég nem jelent problémát a nyelvtechnológia számára, viszont ettől még a feladat bőven rejt magában buktatókat.
Ha elfogadjuk azt a tézist, hogy a big data valódi paradigmaváltás olyan szempontból is, hogy olyan mennyiségű információ kezelésére van szükség, amire a klasszikus módszerek nem alkalmasak, mik lehetnek azok, amik viszont igen? A megoldandó probléma jellegétől függően előfordulhat, hogy a legkomolyabb relációs adatbázis-kezelő rendszerek sem képesek elfogadható futásidő alatt annyi információt kezelni, amennyit szükséges. Itt lépnek képbe a gráf-adatbázisok.
Ahogy írtam, ha átlagosan 7 percenként fut be egy-egy riasztás, esélytelen lenne mindről felelősségteljesen megállapítani, hogy valódi támadási vagy támadási kísérlet-e vagy egyszerűen csak akkor lefutó szkript miatt jelenik meg egy-egy anomália. Viszont közel sem annyira könnyű megállapítani automatizáltan, hogy szokatlan felhasználó magatartásról vagy ún. robotról van szó.
A Balabit kutatói az ember természetes aktivitásának időbeli eloszlását veszik alapul.
Számításba vették, hogy nincs olyan alkalmazott, amelyik folyamatosan dolgozna, míg szkriptek közt természetesen lehetnek olyanok, amiknek folyamatosan vagy bizonyos, pontos időközönként futnak le. Ez pedig markerként használható annak megállapításához, hogy Valamilyen tevékenység közvetlenül emberi eredetű vagy egyszerűen kódfuttatás eredménye.
A robotdetektáló modul második fontos eleme ugyancsak az időre, mint adatforrásra támaszkodik. Egy húsvér felhasználó ha periódusonként vagy rendszeres időközönként is csinál valamit, azt időben nem annyira pontosan kezdi és fejezi be, mint egy robot, ezen kívül a tevékenység időbeli eloszlása mindegy ujjlenyomatként szolgál a felhasználó – vagy éppenséggel robot – azonosításához.
Röviden szólva, a Blindspotter időben riasztást tud kiadni olyan esetben, ha az emberitől eltérő aktivitást észlel a hálózat valamelyik felhasználójánál.

A Neticle szentiment elemzéssel foglalkozó előadásában a hallgatóság megismerkedhetett a műfaj 10 szabályával. A szentiment elemzés egyszerűsítve annak gép feldolgozása, hogy egy-egy adott szöveg milyen érzelmi töltést tükröz, ami közel sem olyan egyszerű, mint amilyennek tűnik. Ugyanis a gép számára alapvetően teljesen strukturálatlan adathalmazt, az emberi szöveget kell elemezhető egységekre bontani, azokat kontextusában vizsgálni. Több buktató viszont csak a tényleges elemzés közben derül ki, például egy 2013-as kutatásban mutatták ki, hogy a felháborodott, negatív hangvételű, dühös vélemények határozottan jobban terjednek mint a neutrális vagy pozitív hozzászólásokban hordozott üzenetek.
Hasonlóan kihívást jelent megtanítani a gépet az irónia kezelésére és osztályozására.

Viszont a jelzős szerkezetek előtt álló negáció azonosítása mára már minden nagyobb nyelvben megoldott.

Nem meglepő módon a gépi alapú elemzés pontosságát nagyban befolyásolja, ha előre tudott, hogy mit is kell elemezni. Így például olyan kifejezés, ami más helyen előfordulva pozitív töltésű lenne, adott szövegkörnyezetben vagy topikban gyakorlatilag nem hordoz semmilyen töltést.

A szövegbányászok egyetértenek abban, hogy ma már nem csak bizonyos írásművek szerzőinek azonosításában lehet segítségükre a nyelvtechnológia, de bizonyos folyamatok akár elő is jelezhetők a hagyományos- és közösségi médiában megjelent tartalmak tömeges elemzésével. Így például már egy 2011. szeptemberében megjelent Nature-cikk is foglalkozott azzal, hogy akár az arab tavasz is elvben előre jelezhető volt, ahogy az az előadásban elhangzott.
A nyelvtechnológiai megoldásokon keresztül azon kívül, hogy elemezhető a múlt és előre jelezhető bizonyos pontossággal a jövő, a nagyobb nyelvek esetén jobb szövegek előállításában is segítséget jelenthet mindenkinek, aki ezzel foglalkozik. Ilyen alkalmazások például a Textio azzal, hogy szinonimákat ajánl az íródó szövegben vagy éppen a Toneapi ami az elkészült szöveg hangulati jellemzőivel kapcsolatban képes egy elemzést adni az újságírók, szerkesztők kezébe.
Az idei Big Data Universen elhangzott előadások diasorai itt érhetők el.
UPDATE: gráfadatbázisokról hamarosan egy másik posztban
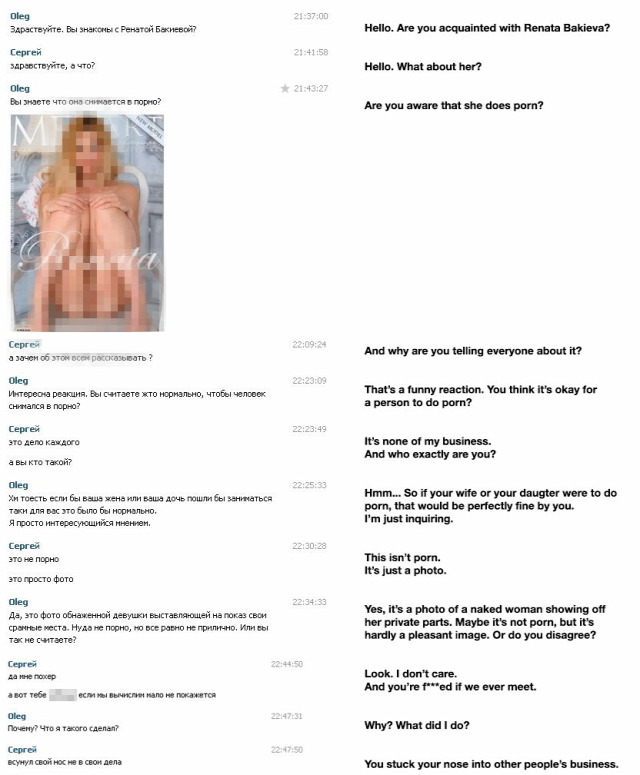
 Mindig is azon a véleményen voltam, hogy többek közt azért rémesen szánalmas dolog siratni a magánszférát a kifogásolható adatkezelési gyakorlatot követő kormányzati szervek, na meg webes óriások miatt, mert nagyságrendekkel nagyobb annak a valószínűsége, hogy a felhasználót a saját hülyesége és az ezzel rendszerint együtt járó exhibicionizmusa kever majd bajba.
Mindig is azon a véleményen voltam, hogy többek közt azért rémesen szánalmas dolog siratni a magánszférát a kifogásolható adatkezelési gyakorlatot követő kormányzati szervek, na meg webes óriások miatt, mert nagyságrendekkel nagyobb annak a valószínűsége, hogy a felhasználót a saját hülyesége és az ezzel rendszerint együtt járó exhibicionizmusa kever majd bajba.





 Ha voksolni lehetne arról, hogy melyik legyen az évtized legrémesebb buzzwordje, alighanem a big data fölényesen nyerne. Mi is a big data? Paradigma, módszertanok összessége? Több vagy kevesebb annál? Erre alighanem csak a jövő fogja megadni a választ, azt viszont nagyon is érdemes tudni, hogy ki az, aki nem csak dobálózik a big data fogalmával és ki az, akinek ugyan lövése nincs az egészről, irkál meg előad a témában bújtatott marketing részeként.
Ha voksolni lehetne arról, hogy melyik legyen az évtized legrémesebb buzzwordje, alighanem a big data fölényesen nyerne. Mi is a big data? Paradigma, módszertanok összessége? Több vagy kevesebb annál? Erre alighanem csak a jövő fogja megadni a választ, azt viszont nagyon is érdemes tudni, hogy ki az, aki nem csak dobálózik a big data fogalmával és ki az, akinek ugyan lövése nincs az egészről, irkál meg előad a témában bújtatott marketing részeként. Hirtelen az jutott eszembe, amikor legutóbb egy számítógépes nyelvészeti konferencián több workshop is volt, ahol több csapat is bemutatott olyan megoldásokat, amiknek a lelkét főként valamilyen
Hirtelen az jutott eszembe, amikor legutóbb egy számítógépes nyelvészeti konferencián több workshop is volt, ahol több csapat is bemutatott olyan megoldásokat, amiknek a lelkét főként valamilyen  Merőben más az az eset, amikor valaki gyakorlatilag bújtatva, de előadja magát fene nagy adatelemzőként, ismer is néhány látványos eszközt, de a tényleges tudás fájdalmasan hiányzik. Márpedig az ilyen nagydumás tahókkal alaposan el lettünk eresztve, akik végülis kifogták a szelet a big data vitorlából. Van-e esélye egy céges döntéshozónak megállapítani, hogy ha adatelemzésről vagy big data módszerek bevetéséről van szó, akivel tárgyal, kókler vagy profi? Az én véleményem, hogy határozottan van.
Merőben más az az eset, amikor valaki gyakorlatilag bújtatva, de előadja magát fene nagy adatelemzőként, ismer is néhány látványos eszközt, de a tényleges tudás fájdalmasan hiányzik. Márpedig az ilyen nagydumás tahókkal alaposan el lettünk eresztve, akik végülis kifogták a szelet a big data vitorlából. Van-e esélye egy céges döntéshozónak megállapítani, hogy ha adatelemzésről vagy big data módszerek bevetéséről van szó, akivel tárgyal, kókler vagy profi? Az én véleményem, hogy határozottan van. A másik, hogy a kóklerek gyakran használnak igencsak látványos, már-már szemet gyönyörködtető ábrákat, dobbantanak demókat, arra viszont már nem tudnának szakmailag elfogadható választ adni, hogy miért pont azt az eszközt használják, amit. Lehet ilyen az SPSS, R, Rapidminer és számos más szoftvercsomag vagy programozási nyelv, ami viszont fontos, hogy a kókler azt használja, amit meg tudott tanulni, a profi pedig azt, ami egy-egy adott feladat megoldásához a legideálisabb!
A másik, hogy a kóklerek gyakran használnak igencsak látványos, már-már szemet gyönyörködtető ábrákat, dobbantanak demókat, arra viszont már nem tudnának szakmailag elfogadható választ adni, hogy miért pont azt az eszközt használják, amit. Lehet ilyen az SPSS, R, Rapidminer és számos más szoftvercsomag vagy programozási nyelv, ami viszont fontos, hogy a kókler azt használja, amit meg tudott tanulni, a profi pedig azt, ami egy-egy adott feladat megoldásához a legideálisabb! Ismét csak azt mondom, hogy a jó kutató ismérve többek közt az, hogy képes holisztikusan is szemlélni egy-egy feladatot, míg a kevésbé tehetséges egy bizonyos fogalomrendszerbe bezárva él. Azt vettem észre, hogy ezzel sajátos módon együtt szokott járni az, hogy a kókler fájdalmasan a mainstreamet majmolja, míg a profi tud és mer teljesen máshogy gondolkozni, hiszen attól profi, jelentős értéket teremteni igazából így lehet. Tény, hogy sokszor nem a téma véleményvezérei a legjobb szakértők, csupán a legismertebbek és nagyon gyakran sokkal sikeresebbek, mint akik tényleg tudnak. Egészen addig, amíg meg nem változik a környezet, aztán bambi. Egy gyökeresen megváltozó környezetben ugyanis a profi képes gyorsan váltani, egy kóklernek viszont ez annyi idejébe telik, amennyi idő alatt a cég becsődöl háromszor. A piaci környezet viszont nem változik gyakran. Legalábbis nem eléggé gyakran, sajnos.
Ismét csak azt mondom, hogy a jó kutató ismérve többek közt az, hogy képes holisztikusan is szemlélni egy-egy feladatot, míg a kevésbé tehetséges egy bizonyos fogalomrendszerbe bezárva él. Azt vettem észre, hogy ezzel sajátos módon együtt szokott járni az, hogy a kókler fájdalmasan a mainstreamet majmolja, míg a profi tud és mer teljesen máshogy gondolkozni, hiszen attól profi, jelentős értéket teremteni igazából így lehet. Tény, hogy sokszor nem a téma véleményvezérei a legjobb szakértők, csupán a legismertebbek és nagyon gyakran sokkal sikeresebbek, mint akik tényleg tudnak. Egészen addig, amíg meg nem változik a környezet, aztán bambi. Egy gyökeresen megváltozó környezetben ugyanis a profi képes gyorsan váltani, egy kóklernek viszont ez annyi idejébe telik, amennyi idő alatt a cég becsődöl háromszor. A piaci környezet viszont nem változik gyakran. Legalábbis nem eléggé gyakran, sajnos.