Sophos Naked Security
Sophos Naked Security Securelist
Securelist cyber-secret futurist
cyber-secret futurist I'm, the bookworm
I'm, the bookworm Még májusban nem kis botrány kerekedett belőle, amikor kiderült, hogy szó sincs arról, hogy a Facebook teljesen automatizáltan jelenítené meg, átkattintások, lájkok, megosztások és egyéb interakciók alapján, hogy a felhasználó falán milyen cikkajánlók jelenjenek meg a nagy lapok tartalmai közül. Konkrétan egy ex-Facebook-alkalmazott először a Gizmodo-nak talált ki azzal kapcsolatban, hogy egy részletes guidelinet kell követnie egy jókora szerkesztőségnek, amivel befolyásolják, hogy milyen forrásból, milyen típusú hírek kerüljenek előtérbe, azzal kapcsolatban pedig a Facebook nem állt elő polkorrekt magyarázattal, hogy miért is. Ugyan erre bármit is mondani kommunikációs hiba lett volna, hiszen enélkül is rájuk verték, hogy az USA-beli liberális tartalmakat preferálják a szerkesztők.
Még májusban nem kis botrány kerekedett belőle, amikor kiderült, hogy szó sincs arról, hogy a Facebook teljesen automatizáltan jelenítené meg, átkattintások, lájkok, megosztások és egyéb interakciók alapján, hogy a felhasználó falán milyen cikkajánlók jelenjenek meg a nagy lapok tartalmai közül. Konkrétan egy ex-Facebook-alkalmazott először a Gizmodo-nak talált ki azzal kapcsolatban, hogy egy részletes guidelinet kell követnie egy jókora szerkesztőségnek, amivel befolyásolják, hogy milyen forrásból, milyen típusú hírek kerüljenek előtérbe, azzal kapcsolatban pedig a Facebook nem állt elő polkorrekt magyarázattal, hogy miért is. Ugyan erre bármit is mondani kommunikációs hiba lett volna, hiszen enélkül is rájuk verték, hogy az USA-beli liberális tartalmakat preferálják a szerkesztők.
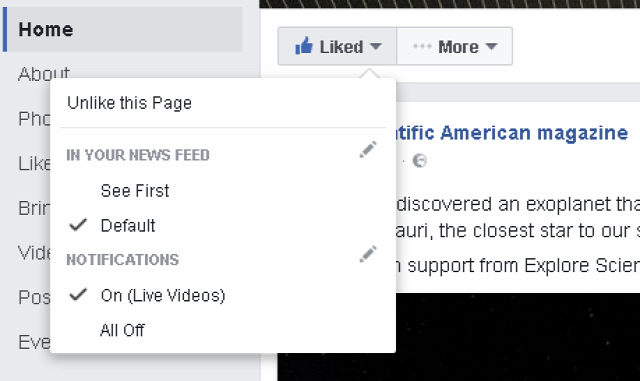
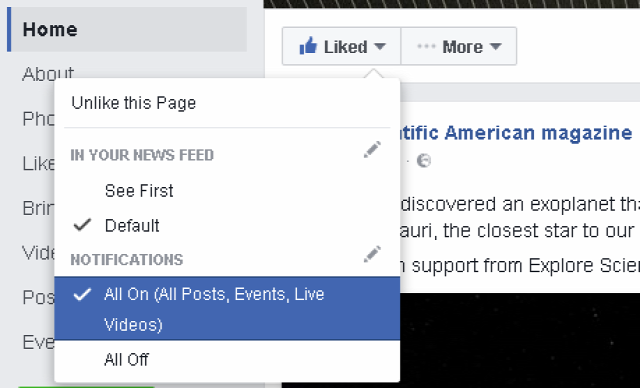
Nehezen hihető, de állítólag nemrég a Facebook a teljes kurátorként dolgozó csapatot menesztette és azt állítják, hogy már valóban csak algoritmusok döntenek arról, hogy mi legyen előtérben a nagy lapok által posztok tartalmak közül, csak különösen indokolt esetbe nyúlnak bele ebbe kézzel. Az eredmény teljesen bejósolható volt: az oldalak elkezdték önteni a veszélyes baromságot, kevésbé rossz esetben álhíreket mindenhonnan, elsősorban a szolgáltatást USA-ban használó felhasználók falára. Másrészt mindez meglátszott azoknak a felhasználók falán is, ahol látszik a Trending box, ami egyenlőre csak amerikai angol nyelven érhető el, bizonyos államokban illetve ha a felhasználó megjelölte a beállítások közt, hogy tud az adott nyelven. A képet az Arsról friss cikkéből csentem:
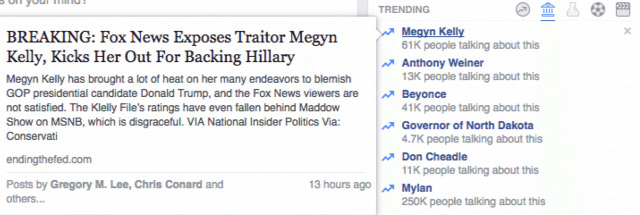
Probléma-e ez? Ha azt nézzük, hogy több friss tudományos kutatás szerint az emberek döntő többségét témafüggően ugyan, de sokszor nem is érdekli a hírek valóságtartalma, még ha érdekelné is őket, nyilván nem mennének minden hír forrásának utána, mondhatni tragikus a helyzet. Ez az egyik magyarázat arra, hogy alapvetően az ostobaság sokkal gyorsabban terjed a neten, amivel összefügg, hogy a nagy átlag jobban harap a gyorsan fogyasztható, érzelmekre, attitűdökre, egyéni értékrendre ható, társadalmi konvenciókat súroló vagy sértő tartalmakra.
Mindez egyébként nem csak a közösségi médiában figyelhető meg. A legnépszerűbbnek számító Google Kereső többek közt annak megfelelően rangsorolja a találatokat, hogy korábbi keresések során, azonos vagy hasonló jelentésű kulcsszavakra keresve a felhasználók mely webhelyekre kattintottak rá, hiszen ebből is következtet arra, hogy mit találtak hasznosnak. Ennek megfelelően az információszerzésnek vannak olyan területei, amire tökéletesen alkalmatlan a Google keresője, tipikusan ilyen az, amikor valaki egy számára ismeretlen gyógyszerre keres rá. A top 10 találatban szinte biztos, hogy olyan leírásokkal fog találkozni, hogy valakinek a gyógyszertől felrobbant a szive, agya, tüdeje, megőrült, detoxba került és így tovább, mivel az sokkal érdekesebb, mivel ezek egyszerűen érdekesebbek, hiába lenne az angol nyelvű Wikipedia egy egészen használható forrás a laikus felhasználóknak is, az pedig szégyen, hogy egy-egy készítményre keresve mennyire sokadik találatként jön elő a gyógyszer ChEMBL, Medlineplus, PubCHEM, IUPHAR, DrugBank, UNII, KEGG, ChEBI vagy éppen Drugs.com adatlapja, holott a legrelevánsabbak nyilván ezek lennének, az más kérdés, hogy nem a leghasznosabbak, mivel az átlag netező fix, hogy nem értené meg. Ebből is látszik, hogy a keresés külön művészet, de most nem ez a poszt témája.
Itt-ott már slágertéma volt, hogy maholnap nem lesz szükség újságírókra és szerkesztőkre azért, mert annyira kifinomult algoritmusok léteznek ma már, hogy azok is képesek lesznek elvégezni a feladatukat. Való igaz, hogy alkottak már olyan algoritmust, ami olyan pontos cikket szerkesztett, amit nem tudtak megkülönböztetni az ember által írt cikktől, ebből azért ennyire messzemenő következtetéseket levonni nem szabadna.
Szerkesztőkre, kurátorokra egyszerűen szükség van és ezt sokan így érzik helyesnek. Tudom, tudom, már-már rögeszmém a téma, de a net hőskorában az volt a szép, hogy mindenkinek a szava nagyjából egyenértékű volt, akár fórumozásról, akár korai blogbejegyzésekről volt szó, a kommentekből pedig a szerző tanulhatott az olvasóitól. Ez a rendszer nagyon szépen működött addig, amíg körülbelül a népesség legiskolázottabb 10-20%-a fért hozzá az internethez, remek kérdés, hogy mikor és mekkora netpenetráció elérésekor jutott el a net egy olyan átbukási ponthoz, amikor a liberális tudásmegosztásból hirtelen anarchia és ordítozás lett, amire különböző szolgáltatók különböző módon válaszoltak. A mindenki által szabadon szerkeszthető hírportálok, mint amilyen volt például a Virtus vagy az Exergum, nem tudták kezelni a jelenséget és megszűntek, a nagy hírportálokhoz becsatornázott blogszolgáltatásokban keletkező posztokat pedig harceddzett szerkesztők lapátolják olyan felületre – magyarul az anyaoldal nyitólapjára - ahonnan történik is átkattintás, különben ma már minden szolgáltatót elöntene a szar. Mi több, ahol heterogén környezetből kell mindig a legfrissebb híreket kiválogatniuk szerkesztőknek, AI-val alaposan megtámogatott szoftverrendszerek segítik a feladatot, az emberi beavatkozás nélkül, ámde hatékonyan működő híraggregátorok, mint amilyen a felhasználó ízlését tanuló Flipboard eleve kézileg előzetesen szűrt forrásokból dolgoznak, azaz annak az ajánlójába aligha kerül be egy 10 perce létrehozott blogról Droid Pisti épületes bölcsessége.
Miért feltételeznénk, hogy a Facebook máshogy működik, ha hírportálok FB-oldaláról van szó? A szerkesztők saját ízlése szükségszerűen mellélőhet azzal kapcsolatban, hogy mi érdekes a felhasználók számára, viszont még mindig összehasonlíthatatlanul kedvezőbb állapot, mintha okos algoritmusok vennék át a gyeplőt, aztán jobb esetben csak a környezetünknek tetsző, ilyen módon némileg egyhangú tartalmakat kapnánk folyamatosan [mivel a FB mindennek kapcsolatban feltételezi, hogy a felhasználó ismerősei hasonlítanak hozzá, így például érdeklődés szempontjából is]. A rosszabb eset pedig az lenne, ha a tömegesen lájkolt, megosztott, kommentelt silány minőségű vagy akár uszító tartalomtól nem lehetne látni a normális tartalmakat vagy csak ésszerűtlen idő- és energiaráfordítással lehetne megtalálni azokat.
Szinte kizárt, hogy a Facebook teljesen és végleg kiiktatta az emberi tényezőt, pláne azért nem, mert emiatt ideig-óráig hőbörgött pár hülye egybites aggyal, a mostani lépés pedig érthetetlen, ugyan ötletelésnek van helye.
Még egyszer: a változtatás csak a nagy, angol nyelvű lapok tartalmait érinti és nem a teljes hírfolyamot, viszont rendkívül tanulságos még így is, ha figyelembe vesszük, hogy mekkora befolyása van annak a tömegre, amit lát.
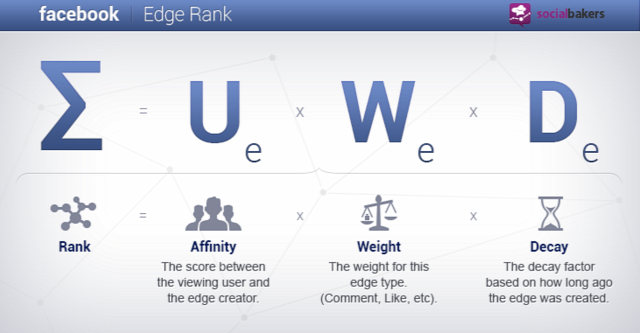
 Amikor kérdezik tőlem, hogy a nyelvtudomány, konkrétabb nyelvtechnológia milyen módon hasznosítható az informatikai biztonság és az igazságügyi informatika területén, az első, ami eszembe jut, hogy milyen módon nem, ugyanakkor nem vagyok egyszerű helyzetben, mivel rendszerint nem ugrik be röviden és informatikusok számára is érthetően summázható, de komoly felhasználási módszer.
Amikor kérdezik tőlem, hogy a nyelvtudomány, konkrétabb nyelvtechnológia milyen módon hasznosítható az informatikai biztonság és az igazságügyi informatika területén, az első, ami eszembe jut, hogy milyen módon nem, ugyanakkor nem vagyok egyszerű helyzetben, mivel rendszerint nem ugrik be röviden és informatikusok számára is érthetően summázható, de komoly felhasználási módszer. Egyszerűek persze vannak: tudtad, hogy egy bizonyos szövegben az írásjelek aránya, a mondatszerkesztés stílusa, többek szerint pedig a leggyakrabban és a legkevésbé gyakran használt 20-20 szó majdhogynem annyira egyedi, mint az ujjlenyomatunk? A nyelvtudomány pedig ötvözve a ma rendelkezésre álló informatikai eszközökkel, egy re elképesztőbb eredményeket érhet el, példaként írom, hogy bő két évvel ezelőtt a Venturebeat írt róla, hogy
Egyszerűek persze vannak: tudtad, hogy egy bizonyos szövegben az írásjelek aránya, a mondatszerkesztés stílusa, többek szerint pedig a leggyakrabban és a legkevésbé gyakran használt 20-20 szó majdhogynem annyira egyedi, mint az ujjlenyomatunk? A nyelvtudomány pedig ötvözve a ma rendelkezésre álló informatikai eszközökkel, egy re elképesztőbb eredményeket érhet el, példaként írom, hogy bő két évvel ezelőtt a Venturebeat írt róla, hogy  A mostani poszt
A mostani poszt 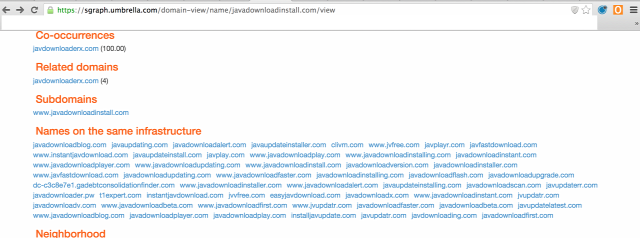
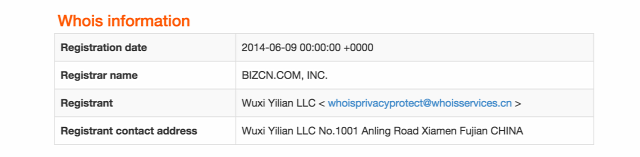
 A kimondottan apró eltéréseket és azok közti távolságot is figyelembe vevő algoritmusok ismerősek lehetnek a bioinformatika területéről, ahol egy-egy, kóros szövetből származó DNS vagy RNS részletének szekvenciáját kell meghatározni, az eltérés pedig egy-egy "betűnyi", azaz nukleotidnyi, egyszeresen vagy többszörösen, egymástól bizonyos távolságban. Ezek az ún.
A kimondottan apró eltéréseket és azok közti távolságot is figyelembe vevő algoritmusok ismerősek lehetnek a bioinformatika területéről, ahol egy-egy, kóros szövetből származó DNS vagy RNS részletének szekvenciáját kell meghatározni, az eltérés pedig egy-egy "betűnyi", azaz nukleotidnyi, egyszeresen vagy többszörösen, egymástól bizonyos távolságban. Ezek az ún.