 Mindig is azon a véleményen voltam, hogy többek közt azért rémesen szánalmas dolog siratni a magánszférát a kifogásolható adatkezelési gyakorlatot követő kormányzati szervek, na meg webes óriások miatt, mert nagyságrendekkel nagyobb annak a valószínűsége, hogy a felhasználót a saját hülyesége és az ezzel rendszerint együtt járó exhibicionizmusa kever majd bajba.
Mindig is azon a véleményen voltam, hogy többek közt azért rémesen szánalmas dolog siratni a magánszférát a kifogásolható adatkezelési gyakorlatot követő kormányzati szervek, na meg webes óriások miatt, mert nagyságrendekkel nagyobb annak a valószínűsége, hogy a felhasználót a saját hülyesége és az ezzel rendszerint együtt járó exhibicionizmusa kever majd bajba.
Alighanem emlékszünk még azokra a kémfilmekre, amikben a képernyőn pörögnek a pofák, majd egyszer csak hopp, megmondja a gép, hogy melyik terrorista van rajta. Ugyanis a hatékony arcfelismerés egy óriási fotóadatbázisban egyetlen átlagos fotó alapján 15 évvel ezelőtt is megoldhatatlan feladatnak tűnt a számításigénye miatt, holott már évtizedekkel korábban is rendelkezésre álltak azok az algoritmusok, amivel ez megoldható. Nem csak az egyre izmosabb és izmosabb szerverek, hanem a cloud computing, magyarosabb nevén felhő alapú számítástechnika aztán elhozta azt, ami korábban csak a filmekben létezett. Az első olyan szolgáltatás, ami kép alapján hatékonyan tud keresni és széles körben alkalmazták is, a Google Képkereső volt, az utópia hirtelen valósággá vált.

A Google persze nem hozta nyilvánosságra, hogy milyen gépi tanuláson alapuló mintázatillesztő módszereket gyúrtak az algoritmusukba, azóta számos más mintázatfelismerő szolgáltatás vált elérhetővé kimondottan képek keresésére. Megjegyzem, mindegy, hogy például DNS-szekvenciákat, plágiumgyanus szövegeket, egy hatalmas hangadatbázisból beszédhangot vagy éppen képeket kell gépileg összehasonlítani azaz illeszteni, sokszor ugyanaz az algoritmus használható teljesen eltérő területeken, ami mégis befolyásolja, hogy melyik megoldás terjedt el a képek, azon belül is a képeken lévő arcok felismerésére alapvetően két tényezőtől függött
- nyilván az alapján, hogy melyik a leghatékonyabb, nem csak pontosság, hanem elfogadható számításigény szempontjából
- a nyílt forráskódú megoldások közt melyiknek a konkrét, leprogramozott megvalósítása terjedt el – hiszen ezzel kapcsolatban gyűlhetett össze a legtöbb tapasztalat, ez volt a legjobban dokumentálva és így tovább
Képfelismerésről korábban már a combinós posztban, azt megelőzően pedig a legelőnyösebb és legelőnytelenebb szelfiket osztályozni képes posztban már írtam.

Még márciusban Maxim Perlin létrehozta a saját arcfelismerő szolgáltatását, a FindFacet ami egy teljesen átlagos, mobillal készült fotón lévő arc alapján dermesztő pontossággal képes megtalálni az archoz tartozó személyt a neten. Nos, azért nem a teljes neten, hanem az orosz facebook-ként is emlegetett VKontakte szolgáltatásban, ott viszont önmagában a profilképek alapján!
Néhány héttel ezelőtt Yegor Tsvetkov orosz fotós elindította a saját projektjét Your Face Is Big Data néven aminek a lényege az volt, hogy a metrón véletlenszerűen lefotózott személyeket azonosított a VK segítségével. A cikk angol magyarázata itt érhető el.
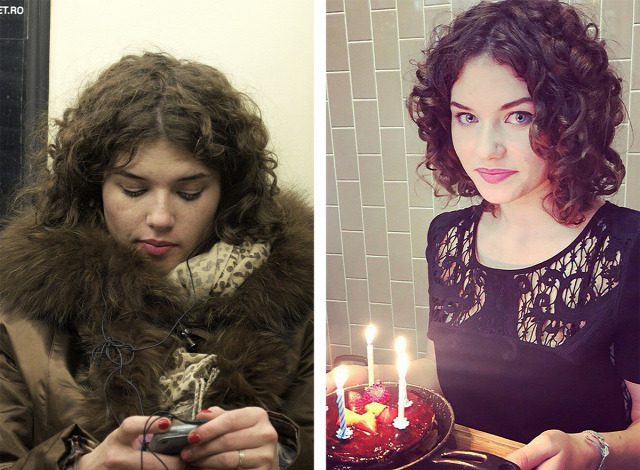
Amire sem a FindFace szolgáltatás fejlesztője, sem pedig a fotós nem gondolt, hogy nem sokkal ezt követően egy 2chan kezdeményezésre trollok hada szállt rá a szolgáltatásra, majd halomra kezdte posztolni a különböző azonosított pornószínésznők személyes adatait. Ugyan próbálták a dolgot egyfajta morális mázzal leönteni, a net pszichológiáját kicsit is ismerők számára könnyen belátható, hogy a valós indíték a nettó nőgyűlölet volt.
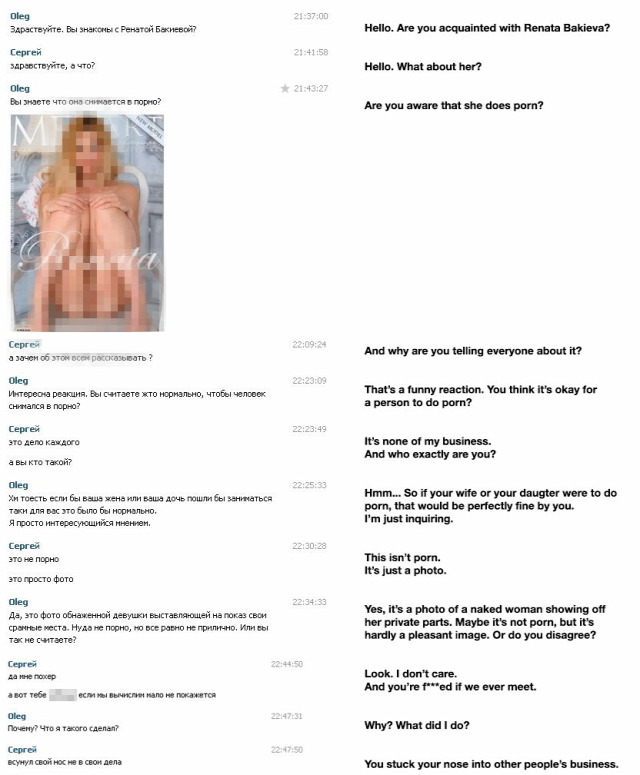
A tanulságot letudhatnánk röviden annyival, hogy ezt a kockázatot be kell vállalni, ha a pornóiparban helyezkedik el valaki, hiba lenne elbagatellizálni azt a kockázatot, ami annak köszönhető, hogy mindenki számára elérhetővé vált egy ennyire hatékony technológia.
A laikus felhasználók számára a Kaspersky Lab állított össze egy posztot a szolgáltatás pontos működésével kapcsolatban, ami azért nagyon fontos, mert a news outlet oldalakon megjelent cikkekkel ellentétben a Kaspersky blogja tisztázza, hogy mi jelent védelmet és mi nem, mikor kell egy felhasználónak tartania tőle és mikor nem, míg a Globalvoices inkább magát a jelenséget járja körül.

1-2 évvel ezelőtt már jelent meg cikk azzal kapcsolatban, hogy a Facebook egyre nagyobb hatékonysággal képes felismeri egy felhasználót akár olyan fotón is, amin nem látszódik a felhasználó arca, csak más testrésze. Ez persze nem jelenti azt, hogy a Facebook a nagyközönség számára elérhetővé is tenne egy olyan funkciót, ami ilyenre lehetőséget ad, jól mutatja, hogy a nagyon-nagyon sok adat alapján úgymond nagyon okossá tud válni egy gép.
Nem titok, hogy a FindFace szolgáltatás lelkét egy hatékony neurális hálózaton keresztül tanuló algoritmus adja, nem világos, hogy mindezt hogyan turbósították, ahogyan az sem, hogy a VKontakte hogyan engedélyezhetett egyetlen külső szolgáltatásnak annyi API lekérdezést, ami a FindFacet ki tudja szolgálni.
 Akit behatóbban érdekel, hogy a big data módszereket hogyan valósítják meg és alkalmazzák, legyen szó akár üzleti folyamatok optimalizálásáról, akár okoskütyükről, annak jó hír, hogy végre lesz Budapesten egy olyan konferencia, ahol olyanok adnak elő, akik nem csak beszélnek róla, hanem ténylegesen értenek is hozzá.
Akit behatóbban érdekel, hogy a big data módszereket hogyan valósítják meg és alkalmazzák, legyen szó akár üzleti folyamatok optimalizálásáról, akár okoskütyükről, annak jó hír, hogy végre lesz Budapesten egy olyan konferencia, ahol olyanok adnak elő, akik nem csak beszélnek róla, hanem ténylegesen értenek is hozzá.
Senkit ne ijesszen el az, ha olyan fogalmakkal találkozik, amikről nincs pontos képe, az előadásokat figyelmesen hallgatva - rémes szóviccel élve - a kevésbé hozzáértők számára össze fog állni a kép. Akik már foglalkoztak big datával, ötletet meríthetnek és bővíthetik az szakmai tájékozottságukat.
Az idei program a Big Data Universe Conference oldalán tekinthető meg.
Képek: Yegor Tsvetkov, Kaspersky Lab

 Sophos Naked Security
Sophos Naked Security Securelist
Securelist cyber-secret futurist
cyber-secret futurist I'm, the bookworm
I'm, the bookworm

