 Akár egy komolyabb fórumon folytatott vitában, akár az igényesen végzett kutatásban szükségessé válhat, hogy ésszerű energiabefektetés mellett meg lehessen állapítani egy adott kijelentésről, hogy ki is mondhatta először. Az első előfordulás megsaccolásának persze számos más területe is lehetséges. Hangsúlyozom, egy-egy kifejezés első előfordulását rendszerint csak megbecsülni lehet, ezek egyike sem bizonyító erejű.
Akár egy komolyabb fórumon folytatott vitában, akár az igényesen végzett kutatásban szükségessé válhat, hogy ésszerű energiabefektetés mellett meg lehessen állapítani egy adott kijelentésről, hogy ki is mondhatta először. Az első előfordulás megsaccolásának persze számos más területe is lehetséges. Hangsúlyozom, egy-egy kifejezés első előfordulását rendszerint csak megbecsülni lehet, ezek egyike sem bizonyító erejű.
Nem akarok túl elméleti felvezetéssel kezdeni, de érdemes tudni, hogy kapcsolódó, de más műfaj az etimológia, ami az önálló kifejezések eredetének feltárásával foglalkozik, ez természetesen magában foglalja, hogy egy kifejezés miből származtatható, hogyan alakulhatott és sokszor azt is, hogy mikor. Az etimológiai eszközökről viszont tudni kell, hogy egy-egy konkrét kérdést nem lehet velük felelősségteljesen megválaszolni mélyebb nyelvtudományi, nyelvtörténeti tájékozottság nélkül. A másik, hogy minél nagyobb korpusz áll rendelkezésre az adott nyelven, annál bőségesebb és pontosabb adatbázisokat tudnak kiépíteni a kutatók, viszont még a legtöbb természetes beszélővel rendelkező nyelvek esetén sem lehet minden kifejezésről 100%-os pontossággal megállapítani a származását és első előfordulását. A magyar pongyolán fogalmazva közepes írásbeliségű nyelv, viszont az etimológiai szótárak közt már több is elérhető a neten, ilyen például a Tótfalusi-féle etimológiai nagyszótár.
Érthetően sokkal nagyobb információtartalommal feltöltött és régebbi, megkockáztatom, hogy az összes közül a legkomolyabb etimológiai adatbázis az Etymonline angol nyelvű változata, ami – az én ismereteim szerint – pontosságában még a több természetes beszélővel rendelkező mandarin kínai, hindi és spanyol etimológiai adatbázisok pontosságát is lepipálja.
Na de mi a helyzet a gyakorlattal? Azaz amikor egy idézet első előfordulását szeretnénk megállapítani. Több eszköz is van, amik közül csak a legegyszerűbbeket említem.
A Google Keresőben adjuk meg a kifejezést idézőjelezve és/vagy válasszuk ki a verbatim keresési módot, ami jelezni fogja a kereső felé, hogy a kifejezés szó szerinti előfordulására vagyunk kíváncsiak. Ezt követően, precízebb találatot kapunk, ha nem a felajánlott opciókat használva, hanem keresőoperátor megadásával állítjuk be, hogy kimondottan időbeli előfordulásra vagyunk kíváncsiak.
Azaz ha arra szeretnénk választ kapni, hogy melyik dokumentumban fordult először elő az a kifejezés, hogy
szökik a málna
akkor a következő keresőkifejezést építhetjük fel. Az egyik valahogy így néz ki
"szökik a málna" before:2016/05/23
természetesen ha nincs találat, akkor a before: és az after: operátorokkal lehet játszani, ezzel szűkíteni a találati halmazt, ami fontos, hogy mivel keresőoperátorokról van szó, a keresőkifejezés literálja(i) után kell, hogy álljanak, csupa kis betűvel, kettősponttal. Ínyencek próbálkozhatnak még a daterange: operátorral, ahol Julianus-naptár szerinti értékkel kell megadni azt a dátumtartományt, amiben a kifejezést keressük.
Bizonyos esetekben hasznos lehet még a Google Trends bevetése, ami ugyan csak tömeges előfordulású kifejezéseknél hatékony, kiindulópontnak jó lehet például olyan szempontból, hogy mikor kezdte el foglalkoztatni a net népét az a téma, amihez az adott fogalom szorosan kapcsolódik.
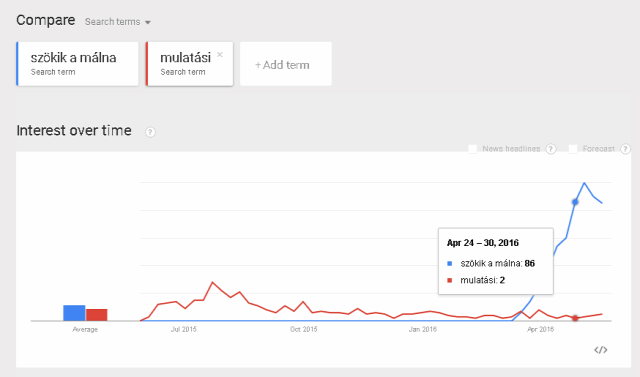
Miért is kezdtem azzal, hogy csak saccolni lehet ezekkel az egyszerű módszerekkel, pontosan megállapítani az első előfordulást nem vagy csak kivételes esetben? A sok-sok ok közül az egyik az, hogy abban az esetben, ha a dokumentum, amiben a kifejezést elsőként szerepelt, már törölve lett, egy idő után a Google indexből is kikerül, így nyilván nem jelenik meg a keresési kifejezések közt, mint gyorsítótárazott tartalom. A másik ok, hogy a Google igencsak hasonlóan olvassa a webhelyeket, ahogyan az ember, márpedig szinte minden korszerű webhelyen vannak olyan dinamikus elemek, amik más-más tartalmat jelenítenek meg a külön-külön lapletöltések alkalmával. Kevésbé kocka módon fogalmazva: gyakorlatilag minden hírportál ajánlgat korábbi vagy éppen újabb cikkeket az alatt a cikk alatt, amit aktuálisan olvasunk, hasonló témában, amit persze a Google is figyelembe vesz. Ez viszont technikai szempontból azt jelenti, hogy hiába fordul elő például az
"részeg árvíztűrő tükörfúrógép támadt a súlytalan rugóra"
egy olyan posztban, ami mondjuk 2016. május 23-án jelenik meg, mivel nem egy statikus oldalról van szó, lévén, hogy közben újabb elemek jelennek meg a cikk alatt, amikor a Googlebot újra pásztázza az oldalt, az ő kis snapshotjához tartozó időbélyeget meg fogja változtatni egy későbbi időpontra, így olyan, mintha a kifejezést valójában csak később írták volna le. Megoldás: nincs mese, a találatok egy részét külön-külön meg kell nézni, és abban látható a poszt, twit, cikk, akármilyen bejegyzéstípus pontos dátuma.
Ezen kívül segíthet még az inurl: operátor, ha azt úgy adjuk meg, hogy az operátor után az URL-ekben gyakran előforduló formában adjuk meg a dátum egy részét. Példa:
"részeg árvíztűrő tükörfúrógép támadt a súlytalan rugóra" inurl:2016/05
persze több találat esetén az inurl: után megadott dátumnál egyre korábbi dátumokkal lehet próbálkozni, de szóba jöhet még az intitle: is.
Soha ne felejtsük el, hogy nem csak Google Search létezik a világon, más-más keresőkben más-más haladó keresési operátorok érhetők el.
Gépház üzen: a kérdésekre nem fogok tudni a megszokott sebességgel válaszolni pár napig :(