
 Sophos Naked Security
Sophos Naked Security Securelist
Securelist cyber-secret futurist
cyber-secret futurist I'm, the bookworm
I'm, the bookworm Amikor kérdezik tőlem, hogy a nyelvtudomány, konkrétabb nyelvtechnológia milyen módon hasznosítható az informatikai biztonság és az igazságügyi informatika területén, az első, ami eszembe jut, hogy milyen módon nem, ugyanakkor nem vagyok egyszerű helyzetben, mivel rendszerint nem ugrik be röviden és informatikusok számára is érthetően summázható, de komoly felhasználási módszer.
Amikor kérdezik tőlem, hogy a nyelvtudomány, konkrétabb nyelvtechnológia milyen módon hasznosítható az informatikai biztonság és az igazságügyi informatika területén, az első, ami eszembe jut, hogy milyen módon nem, ugyanakkor nem vagyok egyszerű helyzetben, mivel rendszerint nem ugrik be röviden és informatikusok számára is érthetően summázható, de komoly felhasználási módszer.
 Egyszerűek persze vannak: tudtad, hogy egy bizonyos szövegben az írásjelek aránya, a mondatszerkesztés stílusa, többek szerint pedig a leggyakrabban és a legkevésbé gyakran használt 20-20 szó majdhogynem annyira egyedi, mint az ujjlenyomatunk? A nyelvtudomány pedig ötvözve a ma rendelkezésre álló informatikai eszközökkel, egy re elképesztőbb eredményeket érhet el, példaként írom, hogy bő két évvel ezelőtt a Venturebeat írt róla, hogy a bitcoin máig ismeretlen megalkotóját elvben lebuktathatja az általa használt nyelvezet. Ahogy egyre jobb és jobb, mesterséges intelligenciára támaszkodó szemantikai szótárak készülnek, nagyon közel állunk ahhoz, hogy egy plágiumot akkor is ki lehessen szúrni, ha azt valaki az eredeti, webről származó doksit más nyelvből fordította és még át is fogalmazta a szöveget! Az erre alkalmas algoritmusok ugyan nem számítanak kimondottan újnak, a IT-számítási kapacitás most érkezik oda, hogy ezek már a gyakorlatban is bevethetők legyenek ésszerű időráfordítás mellett, anélkül, hogy szuperszámítógépeket kellene bérelni méregdrágán és le kellene tölteni hozzá a fél internetet.
Egyszerűek persze vannak: tudtad, hogy egy bizonyos szövegben az írásjelek aránya, a mondatszerkesztés stílusa, többek szerint pedig a leggyakrabban és a legkevésbé gyakran használt 20-20 szó majdhogynem annyira egyedi, mint az ujjlenyomatunk? A nyelvtudomány pedig ötvözve a ma rendelkezésre álló informatikai eszközökkel, egy re elképesztőbb eredményeket érhet el, példaként írom, hogy bő két évvel ezelőtt a Venturebeat írt róla, hogy a bitcoin máig ismeretlen megalkotóját elvben lebuktathatja az általa használt nyelvezet. Ahogy egyre jobb és jobb, mesterséges intelligenciára támaszkodó szemantikai szótárak készülnek, nagyon közel állunk ahhoz, hogy egy plágiumot akkor is ki lehessen szúrni, ha azt valaki az eredeti, webről származó doksit más nyelvből fordította és még át is fogalmazta a szöveget! Az erre alkalmas algoritmusok ugyan nem számítanak kimondottan újnak, a IT-számítási kapacitás most érkezik oda, hogy ezek már a gyakorlatban is bevethetők legyenek ésszerű időráfordítás mellett, anélkül, hogy szuperszámítógépeket kellene bérelni méregdrágán és le kellene tölteni hozzá a fél internetet.
 A mostani poszt apropója egy cikk, ami valahogy csak tegnap jutott el hozzám. Az adathalász emailek és oldalak, amik egy-egy szolgáltatás nevében, annak arculati elemeit felhasználva kérik a felhasználót, hogy adja meg a felhasználói nevét és jelszavát, egyre kifinomultabbak és egyre nagyobb károkat okoznak szerte a világon. Többek szerint a világ legnagyobb bankrablását a Carbanak adathalász kampányon keresztül hajtották végre, ahol a felhasználók emailt kaptak különböző bankok nevében és például arra kérték őket, hogy biztonsági okokból lépjenek be és ellenőrizzék a beállításaikat. Ezt követően egy emailben linkelt adathalász oldalra csalták át őket, a felhasználók többségének pedig nem tűnt fel, hogy a böngésző címsorában lévő cím nem pontosan az a cím, amit akkor szoktak látni, amikor belépnek a megszokott ebanking felületre.
A mostani poszt apropója egy cikk, ami valahogy csak tegnap jutott el hozzám. Az adathalász emailek és oldalak, amik egy-egy szolgáltatás nevében, annak arculati elemeit felhasználva kérik a felhasználót, hogy adja meg a felhasználói nevét és jelszavát, egyre kifinomultabbak és egyre nagyobb károkat okoznak szerte a világon. Többek szerint a világ legnagyobb bankrablását a Carbanak adathalász kampányon keresztül hajtották végre, ahol a felhasználók emailt kaptak különböző bankok nevében és például arra kérték őket, hogy biztonsági okokból lépjenek be és ellenőrizzék a beállításaikat. Ezt követően egy emailben linkelt adathalász oldalra csalták át őket, a felhasználók többségének pedig nem tűnt fel, hogy a böngésző címsorában lévő cím nem pontosan az a cím, amit akkor szoktak látni, amikor belépnek a megszokott ebanking felületre.
Az adathalász kampányt követően az OpenDNS egyik kutatója, Jeremiah O’Connor elkérte az esetről részletes reportot készítő Kasperskytől szinte az összes elérhető adatot. Mindezt azzal a feltevéssel, hogy szofisztikált adathalász kampány ide vagy oda, valamilyen rendszer vagy közös jellemző csak-csak fellelhető az adathalász levelekben. És talált is több ilyen szabályszerűséget, alapvetően a természetes nyelvfeldolgozás eszközeit bevetve.
O’Connor először egy alapos korpuszt épített a scammer levelek szövegezése alapján, ami kiindulási pont egy nyelv vagy nyelvjárás tanulmányozásakor. Az első dolog, aminek megállapításához nyelvtechnológiára sincs szükség, az adathalász levelek azon közös tulajdonsága, hogy egy adott szolgáltató nevéhez hasonló domainre csalják át az áldozatot, ilyen lehet például a microsoft-update-info[.]com, gmailboxes[.]com és hasonlók. Az egyik dolog, ami O’ Connornak feltűnt, hogy az adathalász domainek nevének formátuma rendszerint úgy épül fel, hogy azok tartalmazzák a megcélzott valódi szolgáltatás nevét ehhez van hozzácsapva valamilyen általános kifejezést, ami elaltatja a felhasználó éberségét, ilyen kifejezés lehet például az "update" egy Windows-frissítésre felszólító, valójában az áldozat gépére malware-t telepítő email esetén. Egy jól ismert név és egy általános kifejezés permutációja persze sokféle lehet, de nem végtelen, a felismert szabály alapján egészen pofás kis szótárat épített fel az OpenDNS kutatója, amit valahogy így kell elképzelni egy kamu Java-frissítésre kihegyezett oldal lehetséges neveit.
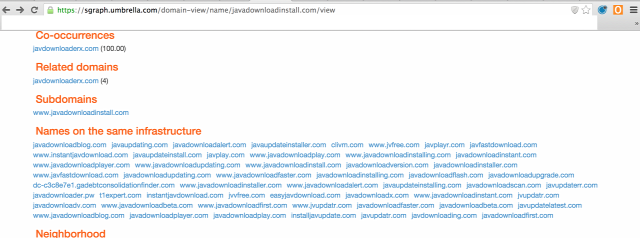
Ezen kívül gyakori még a domainek torzítása hasonló karakterekkel, így például minden további nélkül lehetne regisztrálni az www.0tpbank.hu domain nevet egy adathalász oldal számára. A kutató viszonylag gyorsan tipizálta az adathalász levelekre jellemző nyelvezetet, természetesen nem szorítkozott a domain-nevek elemzésére. A végül elkészült NLPRank-technológia a leveleket egészében értékeli, azaz a gyanus domainekre mutató hivatkozások mellett azt is vizsgálja, hogy egy-egy levél milyen autonóm alhálózatból, ha úgy tetszik, az internet melyik "városából" érkezett. Ha a levél hosszú fejlécében lévő IP-címből az derül ki, hogy olyan AS felől érkezett, amelyik korábban már ontotta az adathalász emaileket, ezt súlyzottan figyelembe vette az algoritmus.
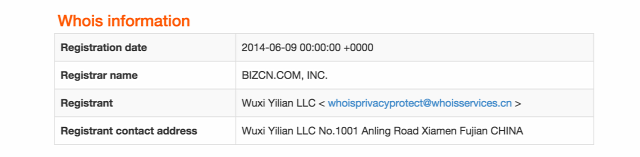
Ezen kívül az adott domainhez tartozó, a domain tulajdonosának adatait tartalmazó WHOIS-rekordban szereplő adatokat vetette össze olyan WHOIS-rekordokkal, amikkel korábban már találkoztak egy biztosan adathalász emailként azonosított domain kapcsán.
Hogy világosabb legyen, hiába regisztrál be egy spambáró mondjuk 100 domaint, a WHOIS-rekord adatai, amik persze maszkoltak, egyezőek vagy nagyon hasonlóak lesznek, ez pedig sok esetben alkalmas arra, hogy ha egy talicska domain ugyanahhoz a szervezethez vagy személyhez tartozik, természetesen akkor is, ha a valódi nevét és elérhetőségeit a WHOIS-rekord nem tartalmazza. A képet az OpenDNS blogjából csentem át, ebben az esetben adathalász oldalak domain-neveinek tömege volt ugyanahhoz a kamu kínai szervezethez beregisztrálva:
Ugyancsak az algoritmus lelkét adja, a domainek hasonlóságának, jelen esetben csaló voltának megsaccolásához kidolgozott módszer. Tekintsük a domain-nevet egy egyszerű sztringnek, azaz szövegnek. Ahogy írtam, az adathalász oldalak címe sokszor csak néhány betűnyi eltérést mutat a legitim szolgáltatás címéhez képest. Mégis, hogyan automatizálható a gyanus domain-nevek szűrése, azaz mikor mondható, hogy alapos rá a gyanú, hogy adathalász oldalról van szó a domain-név alapján? A scammer domain nevek általános sajátosságát figyelembe véve egy domain akkor gyanus, az a leggyakoribb, ha egy jól ismerthez képest két karakterben különbözik. Így például a googlemail.com és a nullásokkal írt g00glemail.com domain név közti különbség éppen két karakternyi, ami pedig nagyon fontos, hogy a szóban forgó lecserélt karakterek egymás közvetlen közelében vannak. Ezen kívül az okos algoritmus, hála a jól felépített szótárnak, azzal is tisztában van, hogy a o-betű nullával való helyettesítése, az l-betű egyes számjeggyel való helyettesítése és hasonlók az adathalász levelekre jellemző sajátosságok.
Ami miatt fontos a felhasználók biztonsága érdekében, hogy automatizáltan felismerhetőek legyenek a gyanus domain nevek, egy igencsak gyakorlati dolog: az OpenDNS névfeloldó szervereire a 60 millió felhasználótól naponta átlagosan 60 milliárdnyi DNS-kérés érkezett már 2015-ben, ha pedig az OpenDNS a névfeloldás szintjén felismeri a veszélyes domain-neveket, időben tudja figyelmeztetni a felhasználót, ha már rákattintott, de akár feketelistára is teheti az adott domain nevet.
 A kimondottan apró eltéréseket és azok közti távolságot is figyelembe vevő algoritmusok ismerősek lehetnek a bioinformatika területéről, ahol egy-egy, kóros szövetből származó DNS vagy RNS részletének szekvenciáját kell meghatározni, az eltérés pedig egy-egy "betűnyi", azaz nukleotidnyi, egyszeresen vagy többszörösen, egymástól bizonyos távolságban. Ezek az ún. SNP-k nagyon sok esetben semmilyen életfunkcióban nem okoznak változást, megint más esetben súlyos betegségeket alakít ki egy-egy nukleotidnyi eltérés.
A kimondottan apró eltéréseket és azok közti távolságot is figyelembe vevő algoritmusok ismerősek lehetnek a bioinformatika területéről, ahol egy-egy, kóros szövetből származó DNS vagy RNS részletének szekvenciáját kell meghatározni, az eltérés pedig egy-egy "betűnyi", azaz nukleotidnyi, egyszeresen vagy többszörösen, egymástól bizonyos távolságban. Ezek az ún. SNP-k nagyon sok esetben semmilyen életfunkcióban nem okoznak változást, megint más esetben súlyos betegségeket alakít ki egy-egy nukleotidnyi eltérés.
A néhol erős egyszerűsítések miatt elnézést kérek! Ahogy korábban is emlegettem, egy olyan korba csöppentünk, ahol minden korábbinál nagyobb szerepet kap az, hogy a kutató, fejlesztő rendelkezzen multidiszciplináris ismeretekkel és ezeket be is vesse, ha kell. Ezért vallom, hogy az egyetemeken, mi több, ahol lehetséges, már középiskolában meg kellene mutatni a tanulóknak, hogy mivel foglalkozik egy-egy cégnél a matematikus, a fizikus, a vegyész, a biológus, a nyelvész, a közgazdász vagy éppen az informatikus. Ugyanis sajnos ha ez elmarad és az egyik szakma képviselőit tömegesen neveli ki úgy a felsőoktatás, hogy még csak egy szemléletes képük sincs arról, hogy más szakmák képviselői mivel foglalkoznak, az nem csak azzal jár, hogy komolyabb helyeken bunkónak nézik őket. A súlyosabb hatás, hogy még csak az esély sem adatik meg nekik, hogy felkeltse az érdeklődésüket valami számukra egészen új dolog [ahogy az én érdeklődésemet felkeltette a nyelvtudomány olyan 24 éves koromban] illetve nem lesznek képesek olyan komplex problémák megoldására, amik az emlegetett multidiszciplináris tudást és holisztikus szemléletet igényelne.
Képek: wordstodeeds.com, komando.com, OpenDNS blog




 Akár egy komolyabb fórumon folytatott vitában, akár az igényesen végzett kutatásban szükségessé válhat, hogy ésszerű energiabefektetés mellett meg lehessen állapítani egy adott kijelentésről, hogy ki is mondhatta először. Az első előfordulás megsaccolásának persze számos más területe is lehetséges. Hangsúlyozom, egy-egy kifejezés első előfordulását rendszerint csak megbecsülni lehet, ezek egyike sem bizonyító erejű.
Akár egy komolyabb fórumon folytatott vitában, akár az igényesen végzett kutatásban szükségessé válhat, hogy ésszerű energiabefektetés mellett meg lehessen állapítani egy adott kijelentésről, hogy ki is mondhatta először. Az első előfordulás megsaccolásának persze számos más területe is lehetséges. Hangsúlyozom, egy-egy kifejezés első előfordulását rendszerint csak megbecsülni lehet, ezek egyike sem bizonyító erejű.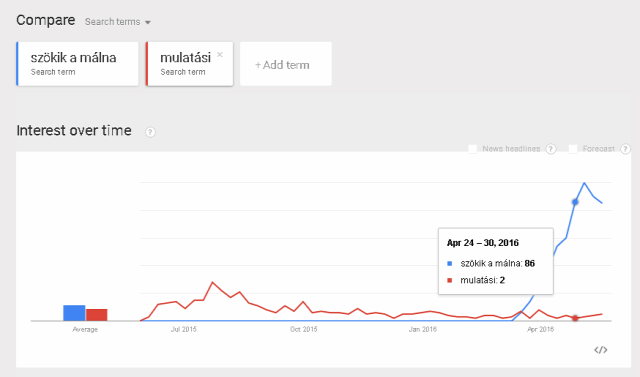
 Nem sok nyomasztóbb téma van annál, mint az, hogy a magyarok mennyire gyengék átlagosan, ha idegen nyelvtudásról van szó. Nem csak a Magyarországon élő magyarok! Ha valaki alaposan szétnéz a tág ismeretségi körében, ideértve mondjuk a volt általános iskolai osztálytársak cikibb felét, nos, azok akik nem amiatt költöztek mondjuk Londonba, mert ott jobb lehetőséget találtak arra, hogy megvalósítsák valamelyik ötletüket, hanem azért, mert nem éppen irigyelni való melóval jobban keresnek, mint Magyarországon, azt találja, hogy hiába élnek kinn több éve, egyáltalán nem biztos, hogy megtanulták a helyi nyelvet. Igaz, hogy idegen nyelvterületen a nyelvtanulás valamennyivel könnyebb, azt viszont csak a full szenilis nagyik gondolhatják, hogy valaki azért tudott megtanulni egy idegen nyelvet, mert külföldön volt vagy hogy ki kell menni külföldre azért, hogy valaki szinte tökéletesen megtanuljon idegen nyelven. Mindkettő egy-egy önmagát makacsul tartó, ostoba és – amint be fogom mutatni: veszélyes – mítosz a nyelvtanulással kapcsolatban.
Nem sok nyomasztóbb téma van annál, mint az, hogy a magyarok mennyire gyengék átlagosan, ha idegen nyelvtudásról van szó. Nem csak a Magyarországon élő magyarok! Ha valaki alaposan szétnéz a tág ismeretségi körében, ideértve mondjuk a volt általános iskolai osztálytársak cikibb felét, nos, azok akik nem amiatt költöztek mondjuk Londonba, mert ott jobb lehetőséget találtak arra, hogy megvalósítsák valamelyik ötletüket, hanem azért, mert nem éppen irigyelni való melóval jobban keresnek, mint Magyarországon, azt találja, hogy hiába élnek kinn több éve, egyáltalán nem biztos, hogy megtanulták a helyi nyelvet. Igaz, hogy idegen nyelvterületen a nyelvtanulás valamennyivel könnyebb, azt viszont csak a full szenilis nagyik gondolhatják, hogy valaki azért tudott megtanulni egy idegen nyelvet, mert külföldön volt vagy hogy ki kell menni külföldre azért, hogy valaki szinte tökéletesen megtanuljon idegen nyelven. Mindkettő egy-egy önmagát makacsul tartó, ostoba és – amint be fogom mutatni: veszélyes – mítosz a nyelvtanulással kapcsolatban. Gimnáziumban német és angol óráim voltak, a tanáraim jöttek-mentek és egyaránt akadt köztük tehetséges nyelvtanár és olyan is, aki tényleg komplett idióta volt, ezt a részt szerintem ugorjuk is át. Ja, azért annyira hirtelen ne. Ugyanis ami aztán tényleg feltette az i-re a pontot, ami a nyelvtanulást illeti, az a szóbeli érettségimen történt. A saját nyelvtanáromnál érettségiztem, aki adott egy tételt, amiben a rágógumigyártás történetéről volt egy rész, amit el kellett olvasni, majd saját szavakkal összefoglalni angol nyelven pár perccel később fejből. A dolog nem volt különösebben bravúros, mivel egyébként is jó és segítőkész tanár vizsgáztatott, de maga a felelet egyenesen szürreális volt. A vizsgáztató tanár mellett ugyanis ült egy másik nyelvszakos tanár, aki rendszeresen elröhögte magát, amikor belekezdtem egy-egy mondatba. Ismerős lehet a szituáció, amikor azt hiszed, hogy valaki ennyire kretén bunkó már nem lehet, aztán utólag esik le, hogy mégis. Felelet közben azt hittem egy ideig, hogy esetleg mögöttem lehet valami, ami annyira szórakoztató vagy szimplán csak bepiált az érettségi elnökkel, de gyorsan rá kellett jönnöm, hogy nem. Mindig akkor röhögött a képembe, amikor egy-egy elakadás után folytattam a feleletet. Tényleg rajtam röhögött! Ha van valami, amire nem számít senki 18 éves érettségiző lurkóként, na az alighanem az, hogy a szóbeli érettségije közben – amikor egyébként is van egy jóadag para – rajta röhög valaki, felelet közben.
Gimnáziumban német és angol óráim voltak, a tanáraim jöttek-mentek és egyaránt akadt köztük tehetséges nyelvtanár és olyan is, aki tényleg komplett idióta volt, ezt a részt szerintem ugorjuk is át. Ja, azért annyira hirtelen ne. Ugyanis ami aztán tényleg feltette az i-re a pontot, ami a nyelvtanulást illeti, az a szóbeli érettségimen történt. A saját nyelvtanáromnál érettségiztem, aki adott egy tételt, amiben a rágógumigyártás történetéről volt egy rész, amit el kellett olvasni, majd saját szavakkal összefoglalni angol nyelven pár perccel később fejből. A dolog nem volt különösebben bravúros, mivel egyébként is jó és segítőkész tanár vizsgáztatott, de maga a felelet egyenesen szürreális volt. A vizsgáztató tanár mellett ugyanis ült egy másik nyelvszakos tanár, aki rendszeresen elröhögte magát, amikor belekezdtem egy-egy mondatba. Ismerős lehet a szituáció, amikor azt hiszed, hogy valaki ennyire kretén bunkó már nem lehet, aztán utólag esik le, hogy mégis. Felelet közben azt hittem egy ideig, hogy esetleg mögöttem lehet valami, ami annyira szórakoztató vagy szimplán csak bepiált az érettségi elnökkel, de gyorsan rá kellett jönnöm, hogy nem. Mindig akkor röhögött a képembe, amikor egy-egy elakadás után folytattam a feleletet. Tényleg rajtam röhögött! Ha van valami, amire nem számít senki 18 éves érettségiző lurkóként, na az alighanem az, hogy a szóbeli érettségije közben – amikor egyébként is van egy jóadag para – rajta röhög valaki, felelet közben. Ha van még valami, ami makacsul tarja magát a nyelvtanulással kapcsolatos tévhitek közt, hogy csak megfeszített erővel, vérrel, verejtékkel lehet megtanulni egy idegen nyelvet. Szorgalom természetesen kell hozzá. Viszont más-más embernél más-más módszer lehet hatékony, amire viszont mindenkinek saját magának kell rájönnie. Ha ez megvan, onnantól kezdve már feszültségektől mentes a nyelvtanulás.
Ha van még valami, ami makacsul tarja magát a nyelvtanulással kapcsolatos tévhitek közt, hogy csak megfeszített erővel, vérrel, verejtékkel lehet megtanulni egy idegen nyelvet. Szorgalom természetesen kell hozzá. Viszont más-más embernél más-más módszer lehet hatékony, amire viszont mindenkinek saját magának kell rájönnie. Ha ez megvan, onnantól kezdve már feszültségektől mentes a nyelvtanulás.  Avagy néhány tény, amit eddig nem tudtál a témában, pedig érdemes tudni róla, szigorúan szubjektíven.
Avagy néhány tény, amit eddig nem tudtál a témában, pedig érdemes tudni róla, szigorúan szubjektíven.