Egyre többször merül fel a kérdés, hogy vajon a webhelyek mennyi információt tudhatnak rólunk, ezt hogyan oszthatják meg egymást közt, arról viszont nem nagyon esik szó, hogy bizonyos adatok és módszerek hogyan tesznek nem csak egyedileg gép szerint, hanem akár a gépet használó felhasználó, mi több, akár név szerint is azonosíthatóvá egy-egy személyt. Jól olvasod, tényleg lehetséges. Előre jelzem, kicsit távolról, az alapoktól indítok.
Egyre többször merül fel a kérdés, hogy vajon a webhelyek mennyi információt tudhatnak rólunk, ezt hogyan oszthatják meg egymást közt, arról viszont nem nagyon esik szó, hogy bizonyos adatok és módszerek hogyan tesznek nem csak egyedileg gép szerint, hanem akár a gépet használó felhasználó, mi több, akár név szerint is azonosíthatóvá egy-egy személyt. Jól olvasod, tényleg lehetséges. Előre jelzem, kicsit távolról, az alapoktól indítok.
Aki az elmúlt másfél évtizedet nem egy kavics alatt töltötte, annak legalább valamiféle elképzelése van arról, hogy ha tetszik, ha nem, egyes webhelyek annyi információt igyekszenek begyűjteni rólunk, amennyit csak tudnak, elsősorban azért, hogy minél inkább számunkra releváns, esetlegesen érdekes hirdetéseket tudjanak megjeleníteni a reklámfelületükön. Ez az ún. kontextusérzékeny hirdetés, ami egyrészt érvényesül például egy szolgáltatáson belül, amire példa, hogy ha könyveket böngészünk az Amazonon, akkor is, ha nem léptünk be és inkognitó módban böngészünk, a webhely hasonló tematikájú könyveket fog ajánlani a böngészés ideje alatt. Sőt, mivel a trendek elemzésén keresztül hatalmas mennyiségű adatot spajzoltak be, ezért azt is jól tudják, hogy ha valaki mondjuk az anonimizálással kapcsolatos könyveket böngészte, akkor sanszos, hogy érdekelni fogja mondjuk valamilyen más geek kütyü, mondjuk kémtoll is, így azt is ajánlgatni fogja a webshop.
A modell természetesen működik webhelyek közt is, gyakorlatilag behálózva a világot, a legismertebb ilyen technológia a Google Adsense, amivel kapcsolatban a legfinomabb, hogy a teljes Google-nek évről évre ez hozza a legnagyobb bevételt. A webhelyek közti működést úgy kell elképzelni, hogy ha egy Adsense-t használó oldalt meglátogatott a felhasználó ami alapján az Adsense sejti, hogy a felhasználónak milyen hirdetést lehet érdemes megjeleníteni, ezt követően ha egy olyan oldalra megy át, ahol még soha korábban nem járt, de szintén Adsense hirdetéseket használnak, akkor ott is eleve olyan termékek illetve szolgáltatások fognak felvillanni hirdetésben, amik feltehetően érdeklik az olvasót, de a korábban meglátogatott oldalak alapján.
A kontextusérzékeny hirdetéseket a Facebook járatta csúcsra, persze kicsit más műfaj, hiszen itt már be kell lépni, ahogy arról már korábban írtam, gyakorlatilag jobban tudja a Facebook azt, hogy mire költenénk szivesen, mint mi magunk, ráadásul a Google-lel ellentétben a hirdetésperszonalizációt még csak ki sem lehet iktatni a szolgáltatáson belül.
Webanalitikai szolgáltatásokról szintén írtam korábban, ezek lényege ugyancsak az, hogy tudjuk, a látogatóinkat milyen tartalmak érdekelték, milyen platformot használnak, általában milyen képernyőfelbontással, honnan kattintanak át az oldalunkra és így tovább, minden ilyen megoldás erősen támaszkodik a JavaScriptre és a sütik kezelésére.
Tehát azok a főbb, régi módszerek, amiket már sok-sok ideje alkalmaznak arra, hogy a felhasználóról valamilyen adatot nyerjenek, a következők:
1. magának a webszervernek a nyers logja, amit valahogy így kell elképzelni
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
[IP-cím]
[URI, azaz, abszolút minden fájl, ami http/https protokollon keresztül folyik át]
4/25/16 5:02 AM
[a tartalom, ami az előbbit meghívta, itt konkrét példával]
http://bardoczi.reblog.hu/telefonbeszelgetes-rogzitese
Megjegyzem, elvben lehetséges, hogy semmilyen információt nem ad át a szervernek a kliens az oprendszer típusáról, a böngészőmotorról, böngészőcsaládról, csak ebben az esetben vagy megtagadja a kiszolgálást a webszerver vagy kiszolgálja ugyan a látogatót, de a tartalom hibásan fog megjelenni. Az okos webanalitikai oldalak az IP-címeket már nagy-nagy adatbázisok alapján földrajzi hellyé „fordítják le”, a legnagyobb adatbázisok pedig dermesztő pontossággal mutatják egy-egy eszköz helyét csupán az IP-cím alapján: http://iplocation.net/
2. sütik a böngészőben – az első olyan technológia volt, amit többek közt azért hoztak létre, hogy a felhasználókat jobban meg lehessen egymástól különböztetni
3. minden más, hibrid módszer – gyakorlatilag a többi csak ezeknek a cizelláltabb változata, például amikor a Google Analytics megoldja, hogy egy süti elhelyezése után egy JavaScript kód folyamatosan értesítse a webanalitikát végző szervert a felhasználó kattintgatásairól
Természetesen minden letiltható, csak éppenséggel ennek az az ára, hogy az elmúlt 10 évben készült webhelyek szinte egyike sem fog működni normálisan.
Feltétlenül szót kell ejteni azokról a technikákról, amik viszonylag újabbak és még ennél is pontosabb azonosítást tesznek lehetővé.
 Az abszolút láma felhasználó esetleg gondolhatja úgy, hogy az IP-cím az azonosítás szent grálja, ezért nagyon gyorsan elmagyarázom az egyik okát, hogy ez miért nincs így, majd azt, hogy ez hogyan változott meg mégis.
Az abszolút láma felhasználó esetleg gondolhatja úgy, hogy az IP-cím az azonosítás szent grálja, ezért nagyon gyorsan elmagyarázom az egyik okát, hogy ez miért nincs így, majd azt, hogy ez hogyan változott meg mégis.
Az otthoni routerünknek vagy a munkahelyi routernek a netszolgáltató leoszt egy IP-címet, erre az IP-címre fogja majd megcímezni az adatcsomagokat az a szerver, amelyikről letöltünk. De ha egy munkahely vagy otthoni hálózat egy IP-címet használ, akkor honnan tudja az adatcsomag, hogy merre kell haladnia, azaz anyuka, apuka vagy a gyerek gépére kell küldeni az adatokat? Úgy, hogy a router, ahogy a nevében is benne van, útválasztást végez, így hálózati címfordítást is. Ez annyit jelent, hogy a router leoszt a lakásban található eszközöknek is külön-külön egy belső, kívülről nem látható címet, majd pontosan annak továbbítja, amit a net felől kapott, amelyiknek kell, kifelé viszont nem látszik, hogy melyik eszköz küldött adatot, mert a router elfedi azt. A belső hálózatra leosztott címek viszont alapesetben nem láthatóak az internet felé és egy, konvenció szerint csak belső hálózatok címzésére használható tartományból kerülnek ki, ami kisebb hálózatok esetén 192.168.1.1-től 192.168.255.255-ig tart. /*ez elvben több, mint 65 ezer gépet jelentene, a gyakorlatban az otthoni routerek 253 eszközt tudnak kezelni, azaz nem osztják le mindet*/
Tehát amikor valamilyen adatcsomagom érkezik a netről, azt a szerver megcímzi a kívülről látható, a világon abban az időben egyedülálló IP-címre, mondjuk a 178.48.105.abc-re, a routerem pedig tudni fogja, hogy lakáson vagy irodán belül már a 192.168.1.15 irányba kell továbbítani, ami jött, mert konkrétan az én gépemet ez fogja azonosítani, az adatot pedig én kértem.
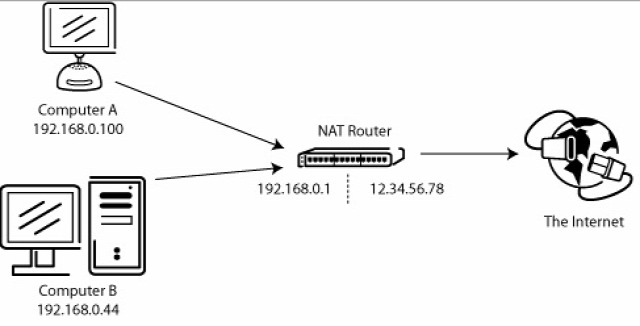
Tételezzük fel, hogy van egy troll, akit egy webhelyről vagy kommentmotorból ki szeretnénk tiltani IP-cím alapján és tudjuk, hogy a címe mondjuk 178.48.105.abc. Éppenséggel meg lehet tenni, viszont ha ezt a címet a netszolgáltató egy kisebb kollégiumnak vagy munkahelynek osztotta le, akkor az IP-alapú tiltással nem csak a problémás látogatót zárom ki, hanem mindenki mást is, hiszen ugyanazon az IP-címen keresztül látnak ki a netre a többiek is és a szerver is csak egy címet lát.
Előbb írtam, hogy a belülre leosztott, azaz ún. LAN IP soha nem látszik az internet felé. Kivéve, amikor mégis. A böngészőben futtatható videócsetes szolgáltatások miatt szükségesség vált kifejleszteni egy olyan megoldást, amivel részlegesen tehermentesíthető a router, kifelé is mutatja a belső IP-címet is, viszont cserébe nem töredezik a kép és a hang videóhívás közben.
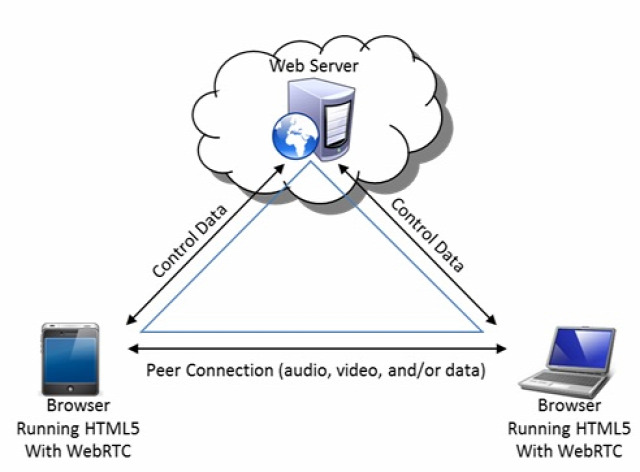
Ezt az ún. WebRTC fölött valósítják meg és gyakorlatilag mára már minden böngésző támogatja. És ahogy mostanra kitalálható a leírásból, a belső IP-címet természetesen nem csak videócsetes szolgáltatások tudják lekérdezni, hanem gyakorlatilag bármi és bárki, aki a webhelyét felkészíti ennek a lekérdezésére. Ez viszont már hatalmas különbség a WebRTC előtti időhöz képest, hiszen megoldható, hogy például egy kommentmotor a trollnak ne csak a publikus IP-címét vegye figyelembe, hanem a LAN IP-jét is, azaz beállítható a tiltás olyan módon, hogy tiltsuk ki azt a gépet, amelyik a 178.48.105.abc IP-vel látható és a 192.168.1.35 LAN IP-cím tartozik hozzá.
Az azonosítás ezen módszerét egyébként a komolyabb szolgáltatások ugyancsak használják, többek közt ez alapján fogja látni a Facebook, ha valaki a saját gépéről lépked be 5 kamu accountjába még abban az esetben is, ha elővigyázatosságból privát böngészőablakot nyit mindhez.
Több ponton persze most egyszerűsítéssel éltem, a LAN IP-k kisebb hálózatok esetén rendszerint változnak, tipikusan egy napig azonosak, de ez lehet egy hét is, esetleg fix.
Mi több, ha eléggé szépen kérdezik a böngészőtől, még azt is kifecsegi, hogy névfeloldó szerverként, azaz DNS1 és DNS2 szerverként mely szervereket használ [ezek azok a szerverek, amikről durva egyszerűsítéssel azt szokták mondani, hogy számokról betűkre fordítják le a szolgáltatások elérhetőségét, azaz a wikileaks.org cím begépelése mellett elérhetjük a Wikileaks oldalát a 95.211.113.154 beütésével is].
Hogy mit láthat aktuális IP-ként, belső IP-ként és használt névszerverként bármelyik weboldal rólunk könnyen ellenőrizhető mondjuk itt:
https://ipleak.net/
A másik, ami idővel szükségessé vált, hogy a webhelyek le tudják kérdezni a látogatójuktól, hogy a böngészőjükben milyen betűtípusok érhetőek el, milyen böngésző kiegészítők vannak telepítve, ezen kívül a reszponzív, okos weboldalaknak tudniuk kell, hogy a tartalmak milyen képernyőfelbontás mellett, milyen színmélységgel jelenítsék meg, mi több, ha átméretezzük az ablakot még azt is látni fogja, hogy mekkorára méreteztük át. Mindezeket vagy önmagában a webhelyen megjelenítéséért felelős HTML5 nyelvvel vagy ún. AJAX-technológiával oldhatujnk meg, de a lényeg, hogy nem csak a megfelelő megjelenítés érdekében használhatjuk, hanem pusztán naplózás céljából is.
Márpedig ha figyelembe vesszük, hogy egy átlagos gép böngészőjében van mondjuk 10 telepített addon, elérhető 50 különböző betűtípus, a böngésző megmondja, hogy milyen felbontású a kijelző, könnyen belátható, hogy gyakorlatilag nincs két egyforma böngésző a világon! És olyan finom részletekbe bele se mentem, mint például az, hogy böngészőbővítmények a verziószámukkal együtt kérdezhetőek le. Az eredmény valami ilyesmi:
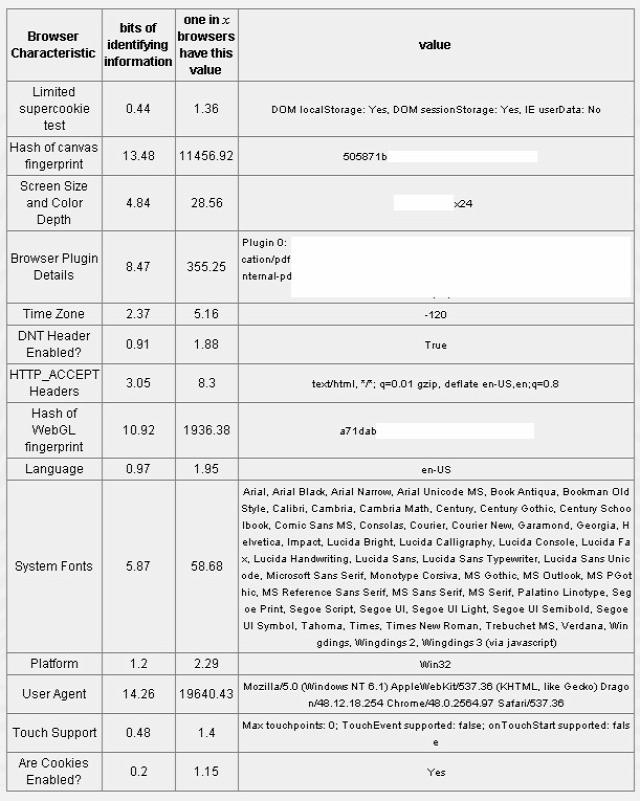
Szemléletesebb, ha mutatom: az egyik legismertebb, browser fingerprinting oldal a https://panopticlick.eff.org/ ahol, miután elvégeztük az alaptesztet, kattintsunk a „Show full results for fingerprinting” feliratra és láss csodát, a webhely jobban ismeri a böngészőnket, mint mi magunk.
Erre felvetődhet a kérdés, hogy mi van akkor, ha valaki hordozható TOR böngészőt használ? A hordozható TOR böngészőben ugye tiltva van számos HTML5, JavaScript funkció, nem futtat fecsegő bővítményeket, de például a NoScriptet mindig, ezen kívül mindegyik ugyanazt a betűkészletet és user-agentet [oprendszer és böngésző típusát mutató változó] kamuzza be a szerver felé, ami annyit jelent, hogy a látogatóról félreérthetetlenül sütni fog, hogy TOR-on keresztül érkezett. A TOR-on keresztül érkező látogatókat pedig egyre több szolgáltatás egyszerűen szögre akasztja és tovább sem engedi.
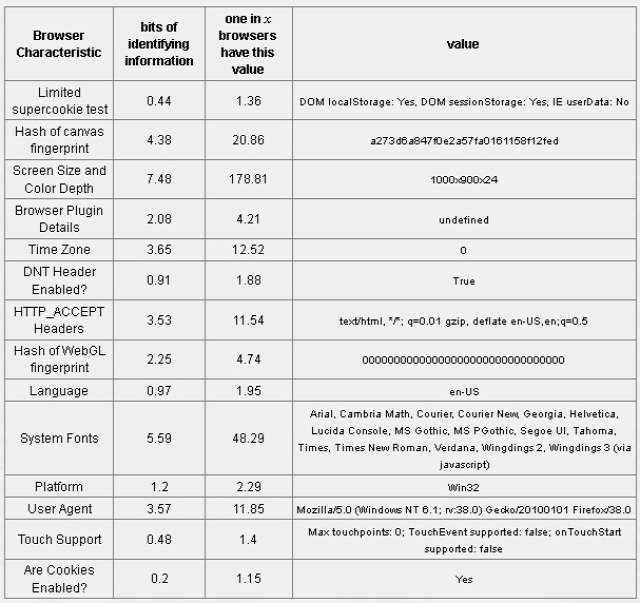
A részletező táblázatban a „bits of identifying information” és a „one in x browsers have this value” sor értelmezése egyszerűsítve annyi, hogy az összes addig tesztelt böngésző közül az adott látogató böngészője mennyire egyedi. Annak az információértéke például, hogy a böngésző angol nyelvű, nem nagy, hiszen alighanem a világon a legtöbben angol nyelven telepítik a böngészőjüket. Annak viszont már eléggé nagy az információértéke egy külföldi oldal számára, ha például a böngésző nyelve magyar, mivel a világ összes böngészője közt relatív keveset telepítenek magyar nyelven. Azaz az egyediség megállapítása az információelméletben alkalmazott egyik alapmodellt alkalmazza, ami szerint az információ nem más, mint a bizonytalanság hiánya, minél kisebb bizonytalanságú valami, annál informatívabb. Másként szólva, minél többet tudunk valamiről, annál jobban alkalmazható azonosításra.
Senkit sem büntetnék a Shannon-Weaver-modellel, de ha valakit érdekel, a szócikk magyarul is egészen jól össze van rakva.
A Panopticlick-tesztben saját magunk jogosítottuk fel a webhelyet, hogy tudjon meg a böngészőnkről mindent, viszont tartsuk észben, hogy a LAN IP és DNS1, DNS2 megszerzését és más böngészősajátosságok lekérdezését és naplózását elvégezheti bármelyik webhely a tudtunk nélkül is!
Jó, jó, de a webszolgáltatások használhatóbbá tételén túl milyen további haszna van annak, hogy a böngészőnk gyakorlatilag a puszta létével ennyit elárul rólunk? Ennek tényleg csak a fantázia szabhat határt, de azért képzeljük el az alábbi eseteket.
Tételezzük fel, hogy szállodaszobát szeretnénk foglalni és a hotelfoglaló oldal látja, hogy egy Apple gépről netezünk, ráadásul céges bérelt vonalon keresztül, ebből egy hozzá kapcsolt algoritmus azt a következtetést vonhatja le, hogy sokkal magasabb árajánlatot dobjon fel, mintha egy öreg windowsos gépen próbálnánk foglalni szobát valamilyen olcsó netkapcsolaton keresztül. A dolog persze messzemenően etikátlan, de a törvény mindenesetre nem tiltja. Túlságosan paranoidnak tűnik? Abból már három évvel ezelőtt botrány volt, hogy egy webshop annak figyelembevételével eltérő árat mutatott más-más felhasználóknak ugyanannak a terméknek az adatlapjánál, hogy a felhasználó helyéhez közel mennyi hasonló profilú üzlet van, pedig egy egyszerű IP-alapú helymeghatározásról volt szó.
Második forgatókönyv: tételezzük fel, hogy valaki kamu Facebook-accountokat hoz létre azért, hogy valakit zaklasson. A Facebook naplózza a legfinomabb részleteket is és simán adódhat úgy, hogy az adott gépről már nem enged új regisztrációt, a meglévőeket pedig egyszerűen jegeli a zaklató valódi fiójával együtt. Ugyanezen az elven, mivel a browser fingerprint naplózva van, többféle webes felületen keresztül történő támadási kísérlet azonosítható, az első esetben a zaklató, a második esetben pedig a szkriptelős hülyegyerek nem gondolhat mindenre, biztos, hogy lebuktatja valamilyen árulkodó nyom, amit hagy maga után. Egy kellően nagy kapacitással rendelkező szervezet akár adatbázist is építhet az ilyen böngésző-ujjlenyomatokból.
A harmadik példa talán a legizgalmasabb. Amikor azonosítani kell egy spammert vagy scammert, elég, ha létrehozunk egy olyan kamu, fingerprintelő webhelyet, majd a címét elküldjük a nigériai főhercegnek mondjuk azzal a szöveggel, hogy oda írtuk fel a számára szükséges adatokat. Emberünk megnézi az oldalt, már meg is van a böngészője ujjlenyomata. A beépített szkriptünkön keresztül az illető nem csak, hogy a teljes böngésző ujjlenyomatát hagyja ott, hanem még az is látható lesz, hogy milyen böngészőbővítményeket és annak milyen verzióit használja. Ez a bűnüldözésben aranybánya – már amennyire a törvény engedi. Például ha ismert, hogy milyen bővítmények milyen verzióval futnak, egy böngésző motor vagy böngészőkiegészítő sérülékenységet kihasználva akár kémprogram is telepíthető az illető gépére, ahogy tette ezt minap az FBI is és nosza, fogtak is párezer pedofilt, na meg gyermekpornográfiában utazó jómadarat példásan rövid idő alatt.
A harmadik technika, amiről nem ejtettem szót eddig, hogy egy kellően ügyes szkript segítségével egy webhely azt is meg tudja állapítani, hogy ilyen-olyan közösségi szolgáltatásokba be vagyunk-e jelentkezve. Ehhez már hozzászokhattunk a social pluginek világában, amikor például nem igényel plusz belépést a kommentelés egy poszt alatt, mivel a plugin felismerte, hogy már bejelentkeztünk a Facebook/Disqus/Twitter-fiókunkkal. A még ügyesebb szkript viszont még annak a megállapítására is képes, hogy egy-egy webhely tud-e lájkoltatni oldalakat a nevünkben, a tudunk nélkül. A lájkvadász mechanizmusok működése végülis a clickjacking, azaz click hijacking, magyarosabban szólva klikk-eltérítés egy speciális esete.
Linus Robbins oldala is sokat el tud árulni rólunk és azt is jelzi, ha például a lájk-eltérítésre érzékeny a böngészőnk.
Ezt egyébként a
http://webkay.robinlinus.com/clickjacking/facebook.html
oldalon lehet ellenőrizni: kijön egy teljesen köznapinak tűnő oldal, amiben ha az ártalmatlannak tűnő folytatás gombra kattintasz, a tudtod nélkül lájkoltad is Linus Robbins oldalát, amit a Facebookon az Activity logban vonhatsz vissza.
A clickjacking ellen ugyan próbál védekezni a Facebook, a lényeg még mindig abban áll, hogy a lájk gombot el lehet rejteni egy, a webhelyen megjelenő átlátszatlan elem, például a „tovább” gomb alá.
Még néhány évvel ezelőtt egy Bestofallworlds-meghívóért egy netes csaló 500 dollárt csalt volna ki egy pénzes német nyugdíjastól és a pénzt persze, hogy Paypal-re kérte, mint később kiderült, nem is volt BOAW-meghívója. A burzsuj szenilis német nyugdíjas csak annyit kért, hogy már küldi is a pénzt, csak az illető kattintson egy linkre, azzal az indokkal, hogy megmutathassa a képeket a nemrég született unokákról. A hülye scammer kattintott, amivel a tudta nélkül lájkolt is egy előre erre a célra létrehozott csali FB-oldalt a saját, valódi Facebook-fiókjával [azt pedig egy FB-oldal adminja azonnal látja, hogy konkrétan ki lájkolta az oldalát és mikor], ami alapján kiderült, hogy nem holland üzletember, hanem egy csóró harmadikvilágbeli pöcs, aki ilyen lehúzásokból él. Ami pedig a történetben nem mellékes, hogy a burzsuj német nyugdíjas valójában én voltam xD
Azaz a netezők pontos azonosításához vagy netes csalások feltárásához nagyon sokszor semmi szükség rá, hogy valamilyen szépnevű hárombetűs szervezet tagjai legyünk, csak egy kis ész, na meg kriminalisztika.
Több szempontból nem javallt, hogy az emlegetett oldalak által ajánlott anonimizáló bővítményeket feltegyük ész nélkül, de abban már nem megyek bele, hogy miért.
Persze, tényfeltáró újságírók, ilyen-olyan aktivisták részéről gyakran felmerülő igény, hogy ne lehessenek azonosíthatók, észben kell tartani, hogy az anonimizálás – amellett, hogy 100%-os sosem lehet – külön tudomány. Ennek megfelelően ha kényes kutatómunkát végez valaki, az általános OPSEC gyakorlat mellett érdemes konzultálni olyannal, akinek az anonimizálási módszerek több éve a kutatási területéhez tartoznak.

 Sophos Naked Security
Sophos Naked Security Securelist
Securelist cyber-secret futurist
cyber-secret futurist I'm, the bookworm
I'm, the bookworm




 Akár egy komolyabb fórumon folytatott vitában, akár az igényesen végzett kutatásban szükségessé válhat, hogy ésszerű energiabefektetés mellett meg lehessen állapítani egy adott kijelentésről, hogy ki is mondhatta először. Az első előfordulás megsaccolásának persze számos más területe is lehetséges. Hangsúlyozom, egy-egy kifejezés első előfordulását rendszerint csak megbecsülni lehet, ezek egyike sem bizonyító erejű.
Akár egy komolyabb fórumon folytatott vitában, akár az igényesen végzett kutatásban szükségessé válhat, hogy ésszerű energiabefektetés mellett meg lehessen állapítani egy adott kijelentésről, hogy ki is mondhatta először. Az első előfordulás megsaccolásának persze számos más területe is lehetséges. Hangsúlyozom, egy-egy kifejezés első előfordulását rendszerint csak megbecsülni lehet, ezek egyike sem bizonyító erejű.
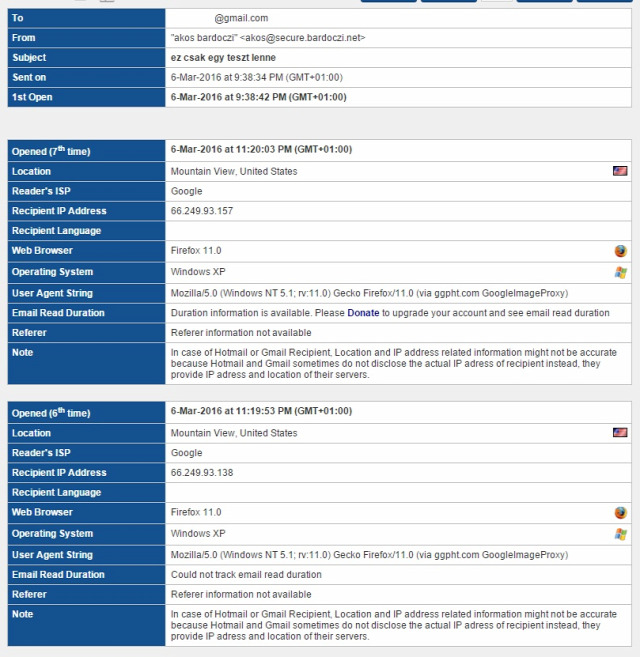
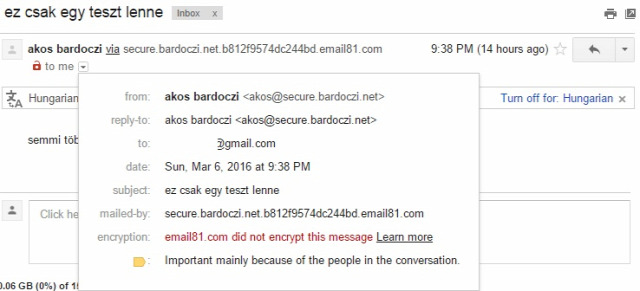
 Amikor emailt küldünk valakinek, annak reményében tesszük, hogy azt a címzett majd el is olvassa. Ugyanakkor bármikor bárki mondhatja, hogy az emailt nem kapta meg, spamben landolt, nem volt még ideje foglalkozni vele, ugyanakkor indokolt esetben, ha a levél kellően fontos volt, tudunk kellene, hogy a levelet a címzett olvasta-e és ha igen, akkor mikor is. Hogyan oldható meg mégis a feladat? Tökéletesen sehogy, de részmegoldás azért van.
Amikor emailt küldünk valakinek, annak reményében tesszük, hogy azt a címzett majd el is olvassa. Ugyanakkor bármikor bárki mondhatja, hogy az emailt nem kapta meg, spamben landolt, nem volt még ideje foglalkozni vele, ugyanakkor indokolt esetben, ha a levél kellően fontos volt, tudunk kellene, hogy a levelet a címzett olvasta-e és ha igen, akkor mikor is. Hogyan oldható meg mégis a feladat? Tökéletesen sehogy, de részmegoldás azért van.  Ahogy írtam, gyakorlatilag egy kihalt lehetőségről van szó, mivel még ha kérünk is ilyen visszajelzést, a címzett levelezőrendszere ezt vagy figyelembe veszi vagy sem, ha támogatott a visszajelzés funkció, a felhasználó még mindig dönthet róla, hogy küldjön visszajelzést, ne küldjön visszajelzést, esetleg a levelezőrendszer rá se kérdezzen, így soha senkinek ne küldjön olvasottsági visszajelzést.
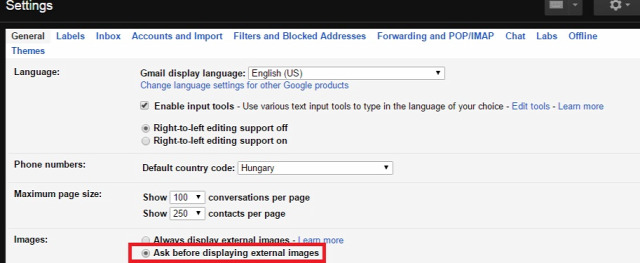
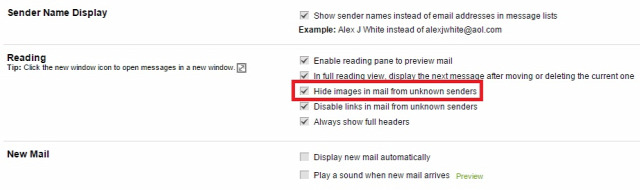
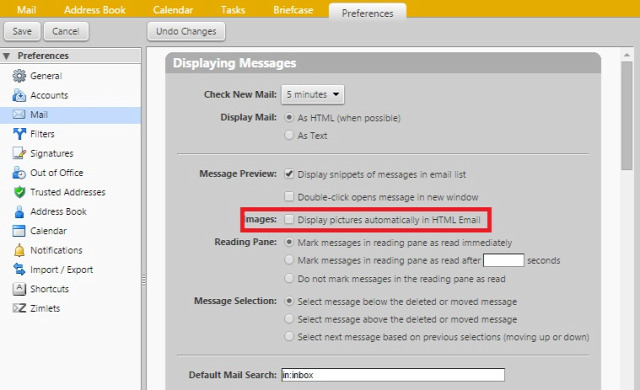
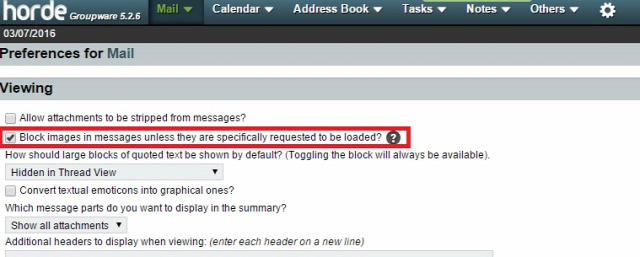
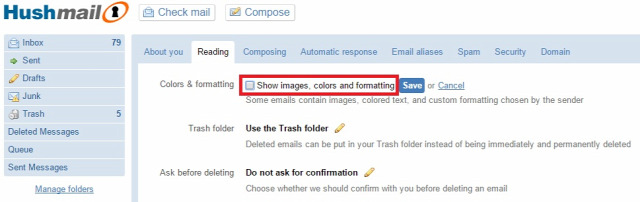
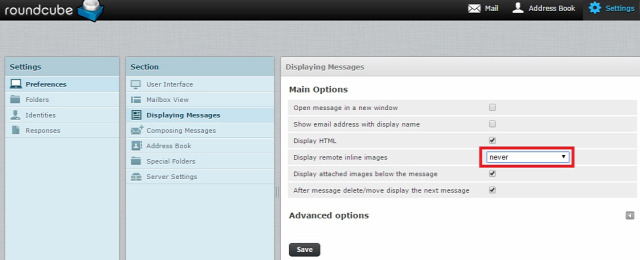
Ahogy írtam, gyakorlatilag egy kihalt lehetőségről van szó, mivel még ha kérünk is ilyen visszajelzést, a címzett levelezőrendszere ezt vagy figyelembe veszi vagy sem, ha támogatott a visszajelzés funkció, a felhasználó még mindig dönthet róla, hogy küldjön visszajelzést, ne küldjön visszajelzést, esetleg a levelezőrendszer rá se kérdezzen, így soha senkinek ne küldjön olvasottsági visszajelzést.  Sok-sok évvel ezelőtt már minden jólnevelt levelezőkliensben és webes levelezőrendszerben alapértelmezés volt, hogy a HTML-formátumú levelekben lévő távoli szerveren tárolt képeket nem tölti le automatikusan, hanem rákérdez a felhasználónál, hogy letöltse-e azokat. Ha a felhasználó úgy döntött, hogy ne töltse le, akkor a feladó nem értesült róla, hogy a címzett a levelet megkapta-e. Viszont könnyen lehet, hogy a címzett egyszerűen nem tudta elolvasni a levelet, mert ilyen-olyan lényegi információk nem szöveges formátumban, hanem egy képre írva voltak a levélben, mint például egy szilveszteri parti helyszíne. Így ha a címzettet érdekelte a dolog, mindenképp le kellett töltenie a képet, mint külső tartalmat is.
Sok-sok évvel ezelőtt már minden jólnevelt levelezőkliensben és webes levelezőrendszerben alapértelmezés volt, hogy a HTML-formátumú levelekben lévő távoli szerveren tárolt képeket nem tölti le automatikusan, hanem rákérdez a felhasználónál, hogy letöltse-e azokat. Ha a felhasználó úgy döntött, hogy ne töltse le, akkor a feladó nem értesült róla, hogy a címzett a levelet megkapta-e. Viszont könnyen lehet, hogy a címzett egyszerűen nem tudta elolvasni a levelet, mert ilyen-olyan lényegi információk nem szöveges formátumban, hanem egy képre írva voltak a levélben, mint például egy szilveszteri parti helyszíne. Így ha a címzettet érdekelte a dolog, mindenképp le kellett töltenie a képet, mint külső tartalmat is.